Dans les coulisses de l'Open Code Quest : comment j'ai conçu le Leaderboard
Lors du Red Hat Summit Connect France 2024 , j’ai animé un atelier pour les développeurs intitulé “Open Code Quest”. Dans cet atelier, les développeurs devaient coder des micro-services en utilisant Quarkus, OpenShift et un service d’Intelligence Artificielle : le modèle Granite d’IBM. L’atelier était conçu sous la forme d’une compétition de vitesse : les premiers à valider les trois exercices ont reçu une récompense.
J’ai conçu et développé le Leaderboard qui affiche la progression des participants et les départage en fonction de leur rapidité. Facile ? Pas tant que ça car je me suis imposé une figure de style : utiliser Prometheus et Grafana.
Suivez-moi dans les coulisses de l’Open Code Quest : comment j’ai conçu le Leaderboard !
Description de l’atelier
L’atelier Open Code Quest a été conçu pour accueillir 96 participants devant réaliser et valider 3 exercices. Valider la bonne réalisation d’un exercice n’implique pas de lire le code du participant : si le micro-service démarre et répond aux requêtes, c’est validé ! Il n’y a donc pas de dimension créative, c’est une course de vitesse et d’attention (il faut juste bien lire l’énoncé).
Le coeur de l’atelier est une application web de simulation de combat entre super-héros et super-vilains. Il y a trois exercices :
- Développer et déployer le micro-service “hero”
- Développer et déployer le micro-service “villain”
- Développer et déployer le micro-service “fight”
Pour plus de détails, je vous renvoie à l’énoncé de l’atelier.
Besoins
Le Leaderboard doit permettre deux choses :
- encourager les participants en introduisant une dose de compétition
- déterminer les 30 participants les plus rapides pour leur remettre un prix
Dans les précédentes éditions de cet atelier, on validait la bonne réalisation sur la base de captures d’écran envoyées sur un channel Slack. Les participants envoyaient les captures d’écran, l’animateur les validait dans l’ordre, notait les points dans une feuille Google Sheet et annonçait la progression à intervalle régulier. Un animateur était dédié à la gestion du leaderboard.
Cette année, il était attendu que le processus soit entièrement automatisé pour éviter ces tâches administratives chronophages.
Principe de fonctionnement
Je le disais en introduction, pour la réalisation de ce Leaderboard je me suis imposé une figure de style : utiliser Prometheus et Grafana. Prometheus est une base de données time series. C’est à dire qu’il est optimisé pour stocker l’évolution de données numériques au cours du temps et faire des statistiques sur ces données. Grafana permet de présenter les données de Prometheus sous la forme de tableaux de bord.
Ces deux outils sont beaucoup utilisés dans deux produits que l’on a utilisés pour cet atelier : Red Hat OpenShift Container Platform et Red Hat Advanced Cluster Management.
Prometheus est très efficace pour savoir que “le Pod X dans le namespace Y vient de passer à l’état Running”. Et c’est justement ce qui nous intéresse :
- Si le Pod hero-database-1 est créé dans le namespace batman-workshop-prod alors on sait que l’utilisateur batman vient de terminer le déploiement de la base de donnée de l’exercice hero dans l’environnement de prod.
- Si le Deployment hero dans le namespace batman-workshop-prod passe à l’état Available, alors on sait que l’utilisateur vient de déployer avec succès son micro-service hero.
- Si un Pod batman-hero-run-<random>-resync-pod dans le namespace batman-workshop-dev passe à l’état Completed, alors on sait que le dernier pipeline Tekton l’utilisateur vient de terminer avec succès.
Et si les trois conditions précédentes sont vraies, on peut en déduire que l’utilisateur a terminé et validé l’exercice hero. Au cours du temps, ces time series progressent telles que représentées sur la figure suivante.
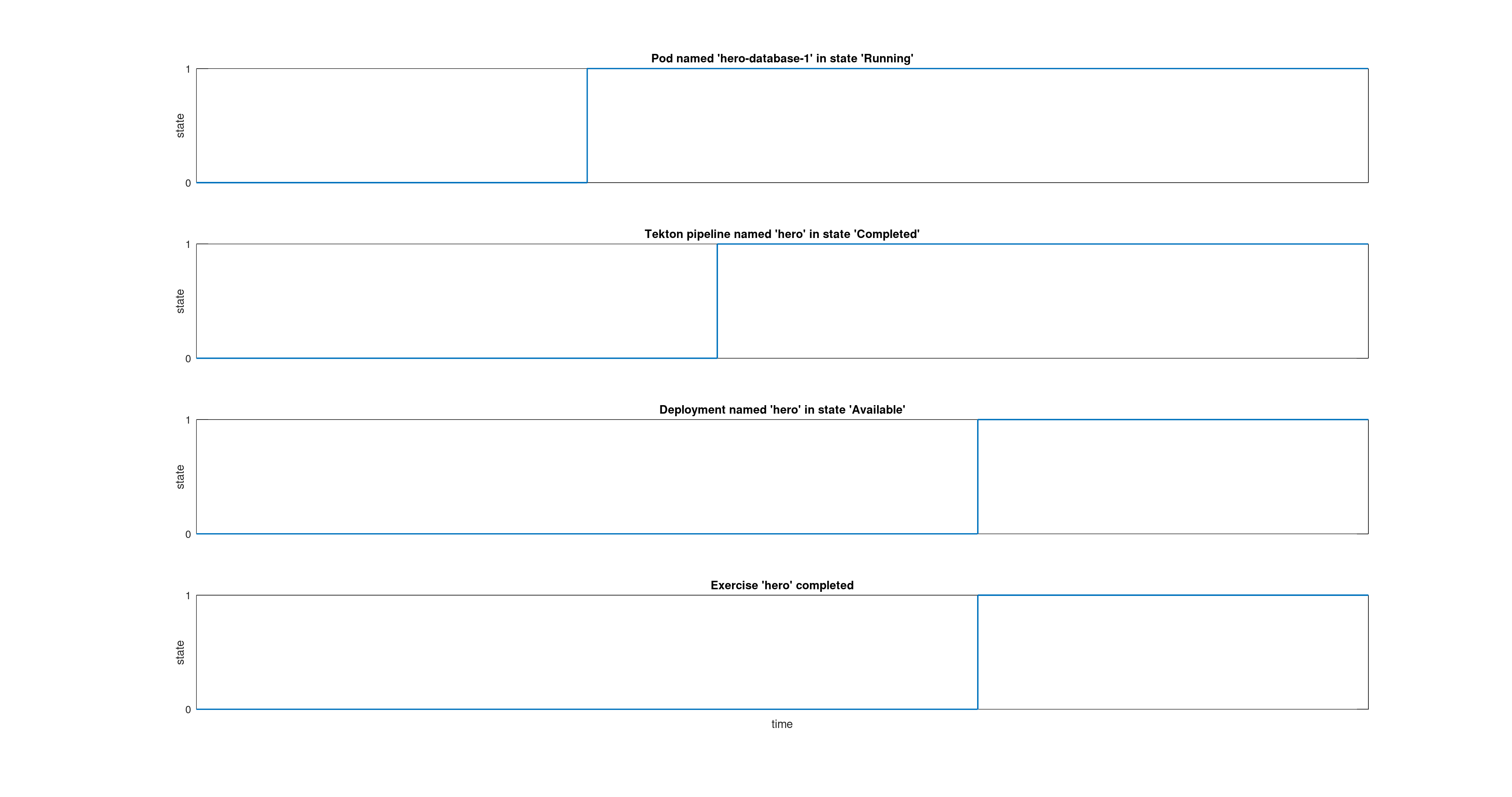
C’est un bon début, non ? Si on fait la même chose pour les trois exercices, on peut savoir qui a terminé l’atelier dans son ensemble.
Vu que certains exercices prennent plus de temps que d’autres, on peut imaginer attribuer plus de points aux exercices longs et moins aux exercices courts. C’est ce que j’ai essayé de modéliser dans la figure ci-dessous avec un poids de 55 pour le premier exercice, 30 pour le second et 45 pour le dernier. L’idée étant d’approcher une progression linéaire des points au cours du temps (1 point par minute).
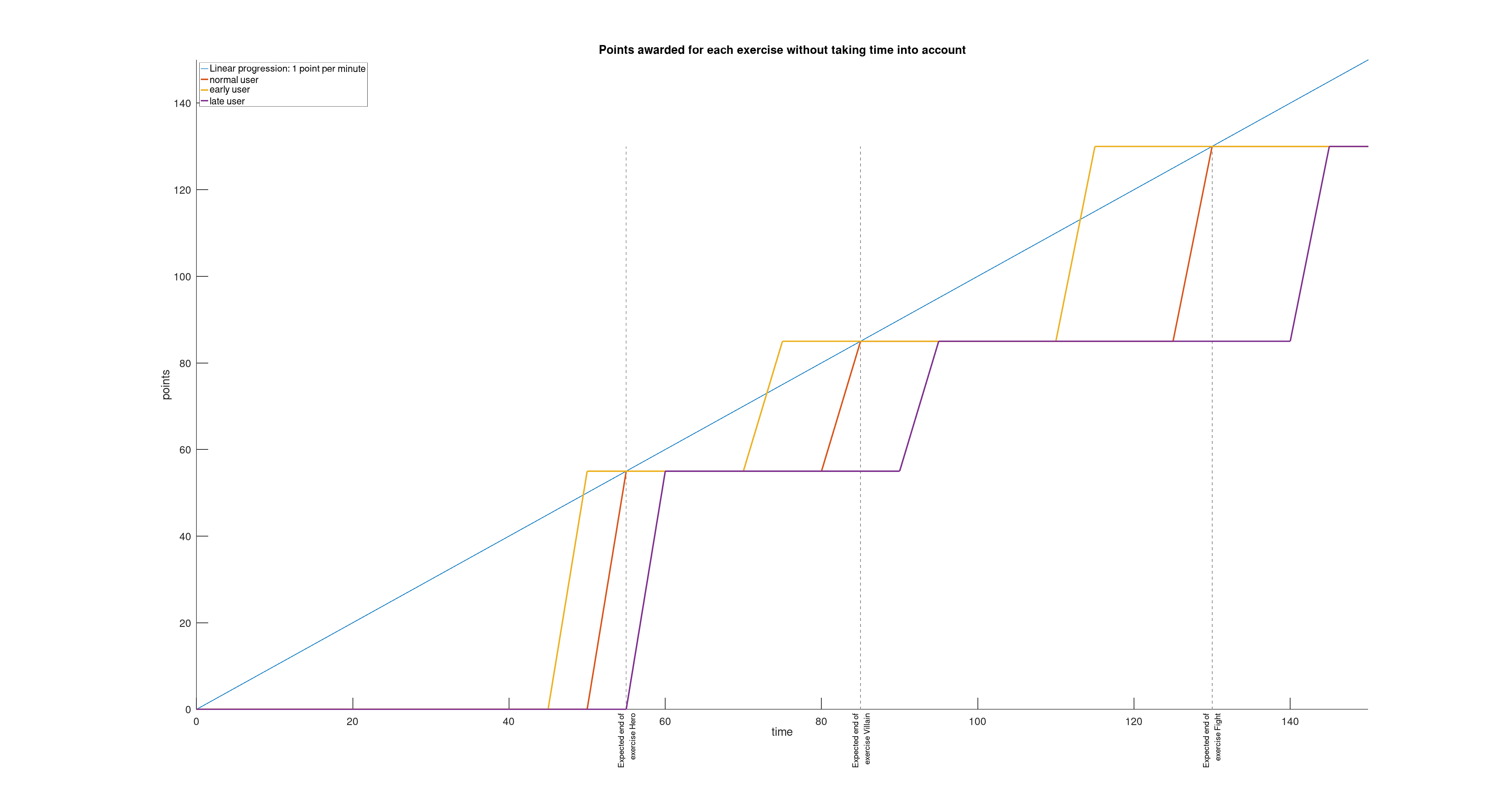
Ça commence à prendre forme. Mais si on regarde bien, à la fin de l’atelier (à la 150ème minute), tous les participants ont terminé et ont le même score.
Et cela me pose deux problèmes :
- Pour commencer, trier des participants par ordre d’arrivée, Prometheus ne sait pas faire. Et je n’ai pas envie, au moment de la remise des prix de devoir analyser les résultats minute par minute pour noter manuellement l’ordre d’arrivée des participants.
- Ensuite, si tous les participants ayant validé un exercice ont le même score, où est le frisson de la compétition ?
Je sais bien qu’avec n’importe quel base de données SQL on aurait juste à faire un SELECT * FROM users ORDER BY ex3_completion_timestamp ASC pour avoir le résultat.
Je sais bien que j’essaye d’utiliser Prometheus pour une tâche qui n’est pas vraiment la sienne.
Mais, soyons fous…
Rêvons deux minutes…
Et si on essayait de contourner cette limitation de Prometheus ?
Est-ce qu’on ne pourrait pas modérer ou accentuer la pondération d’un exercice en fonction du temps qu’a mis l’utilisateur à réaliser l’exercice ?
Est-ce qu’on ne pourrait pas activer un accélérateur à chaque validation d’un exercice qui donnerait quelques points en plus à chaque minute qui passe ?
Voilà qui rendrait la compétition plus engageante et plus amusante !
Et c’est ce que j’ai essayé de modéliser sur le schéma ci-dessous.
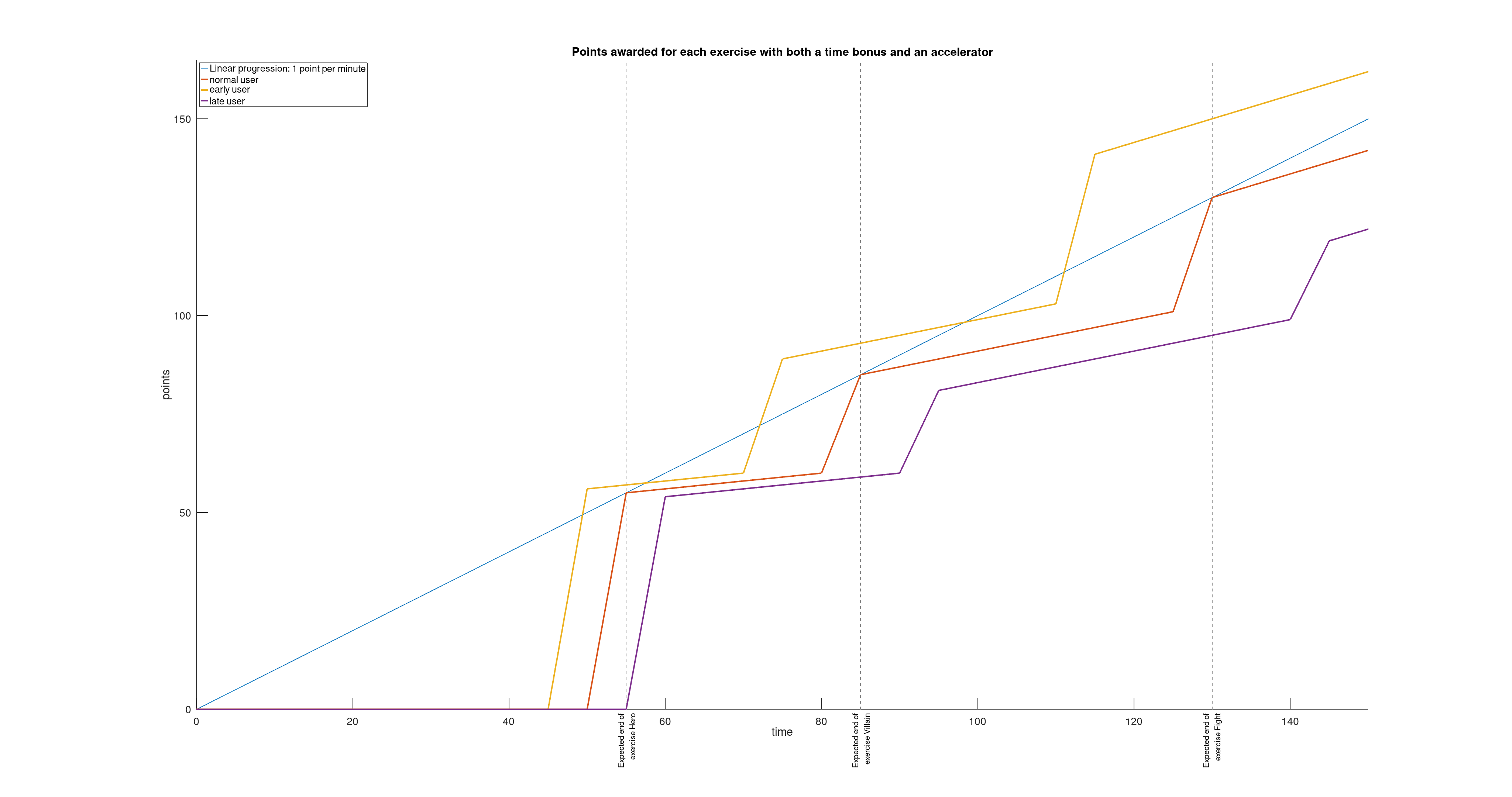
Maintenant, la question est : est-ce qu’un utilisateur qui prend la tête dans le premier exercice acquiert un avantage significatif qui rendrait la compétition déséquilibrée ? La réponse, nous l’avons obtenue lors des différentes répétitions qui ont eu lieu chez Red Hat avant le Jour J.
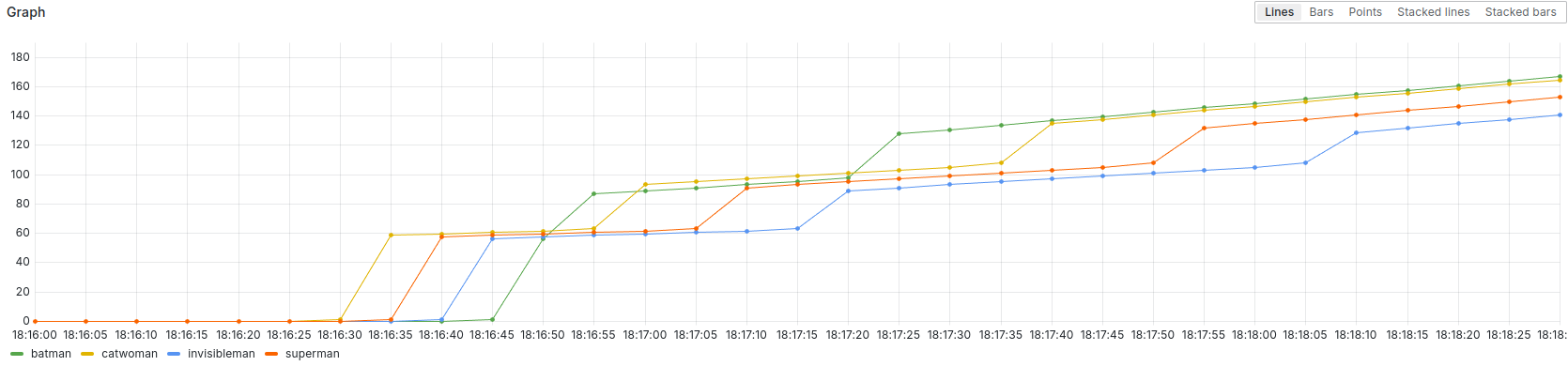
Dans la capture d’écran ci-dessus, on voit que Batman a terminé l’exercice “hero” tardivement.
Mais en terminant l’exercice “villain” très rapidement, il a pu reprendre la tếte… temporairement.
Catwoman qui menait le jeu, lui repasse devant avant que Batman ne reprenne la tête et ne conserve son avance jusqu’au dernier moment.
Ouf ! Quel suspense !
Donc, il est définitivement possible de partir en retard et de rattraper son retard.
Le principe est validé ! Et maintenant, comment est-ce qu’on implémente ça dans Prometheus ?
Implémentation dans Prometheus
Si j’avais dû mettre au point ce système de comptage des points dans un Prometheus pré-configuré pour de la production, j’aurais fait face à deux difficultés :
- Par défaut, la résolution temporelle du couple Prometheus + Grafana inclus dans Red Hat Advanced Cluster Management est de 5 minutes (ça correspond au pas de temps minimum entre deux mesures). Valider le bon comptage des points avec une résolution de 5 minutes sur un atlier de 2h30 prend 2h30 (vitesse réelle).
- Pour implémenter ce système de comptage des points, j’ai besoin d’utiliser des recording rules. Or, la modification d’une recording rule ne déclenche pas automatiquement la réécriture des time series calculées dans le passé.
Pour ces deux raisons, j’ai décidé de passer par un banc d’essai spécifique.
Utilisation d’un banc d’essai
Les spécificités de ce banc d’essai sont les suivantes :
- La périodicité de scrapping de Prometheus est configurée à 5 secondes. Ainsi, valider le bon comptage des points se fait 60 fois plus vite: 2h30 d’atelier se valide en 2m30, avec une résolution de 5 minutes.
- À chaque itération, le Prometheus est reconfiguré avec les nouvelles recording rules, les times series passées sont effacées et Prometheus démarre immédiatement l’enregistrement des nouvelles time series à partir d’un jeu de données de test standardisé.
La mise au point est donc grandement facilitée !
Le banc d’essai est disponible dans l’entrepôt Git opencodequest-leaderboard et ne nécessite que peu de pré-requis : git, bash, podman, podman-compose ainsi que la commande envsubst. Ces dépendances sont habituellement installable avec les paquets de votre distribution (dnf install git bash podman podman-compose gettext-envsubst sur Fedora).
Récupérez le code du banc d’essai et démarrez-le :
git clone https://github.com/nmasse-itix/opencodequest-leaderboard.git
cd opencodequest-leaderboard
./run.sh
Au premier démarrage, connectez-vous à l’interface de Grafana (http://localhost:3000) et réalisez ces 4 actions :
- S’authentifier avec le login admin et le mot de passe admin.
- Définir un nouveau mot de passe administrateur (ou juste cliquer sur Skip…)
- Configurer une source de données par défaut de type Prometheus avec les valeurs suivantes :
- Prometheus server URL:
http://prometheus:9090 - Scrape interval:
5s
- Prometheus server URL:
- Créer un nouveau dashboard depuis le fichier grafana/leaderboard.json qui est dans l’entrepôt Git.
Des données doivent normalement apparaître dans le tableau de bord Grafana.
Pour en profiter pleinement, arrêtez le script run.sh avec un appui sur Ctrl + C et relancez le !
Au bout de quelques secondes, vous devriez voir apparaitre sur le tableau de bord des données toutes fraiches, comme dans la vidéo ci-dessous.
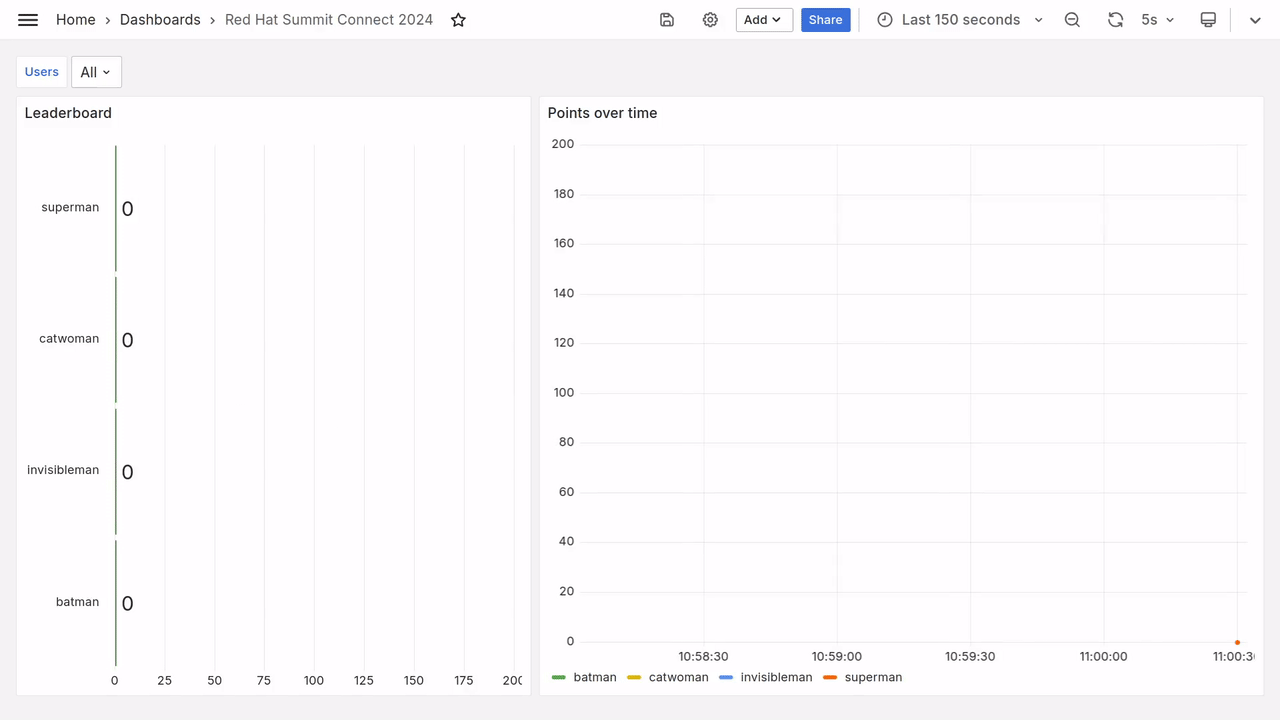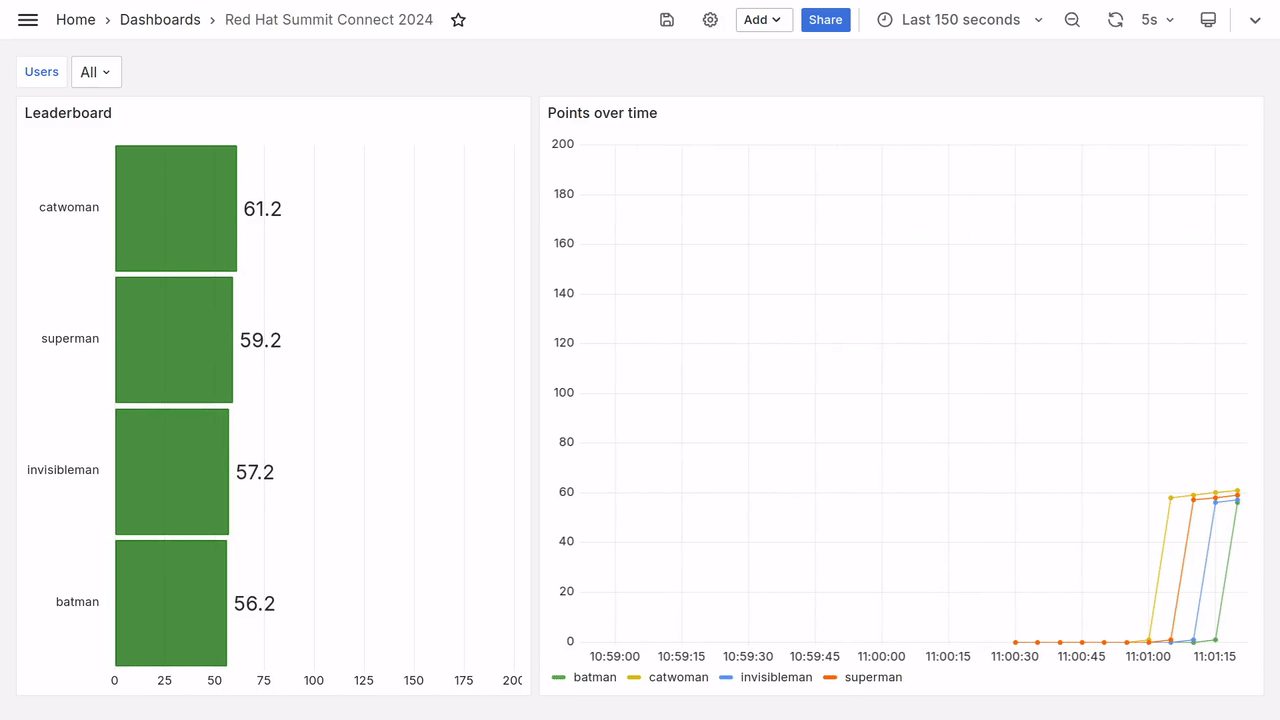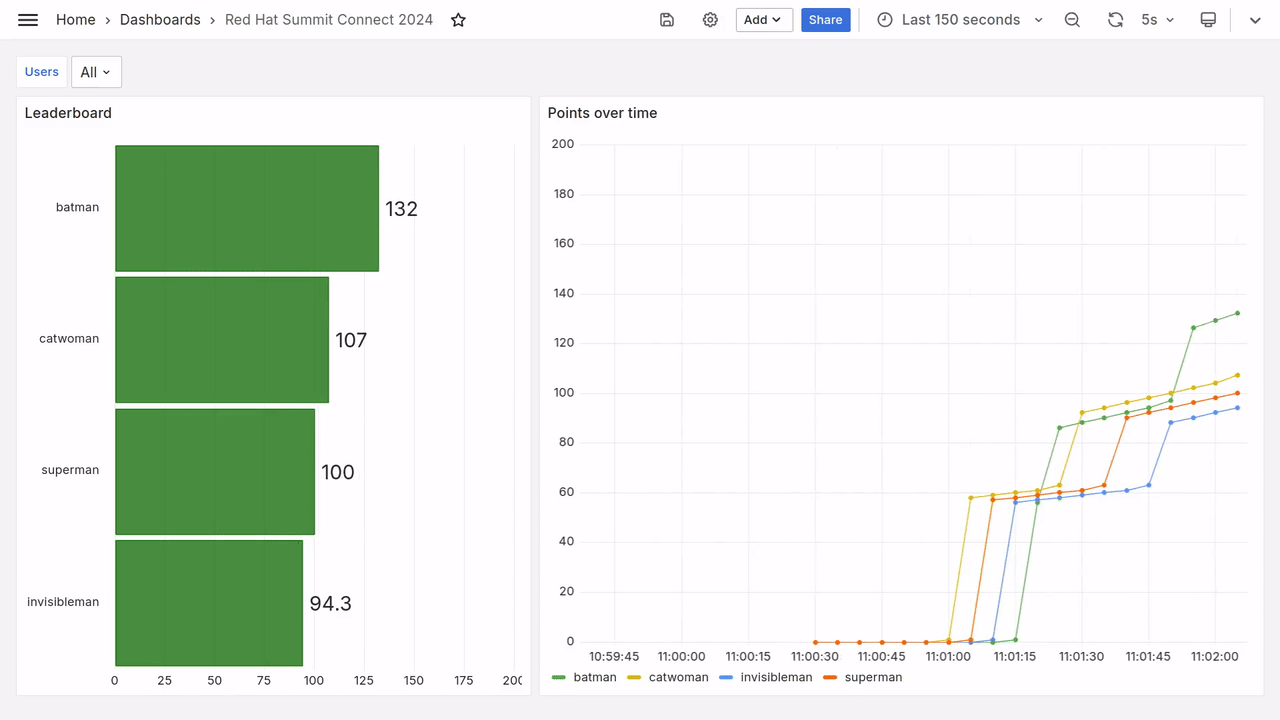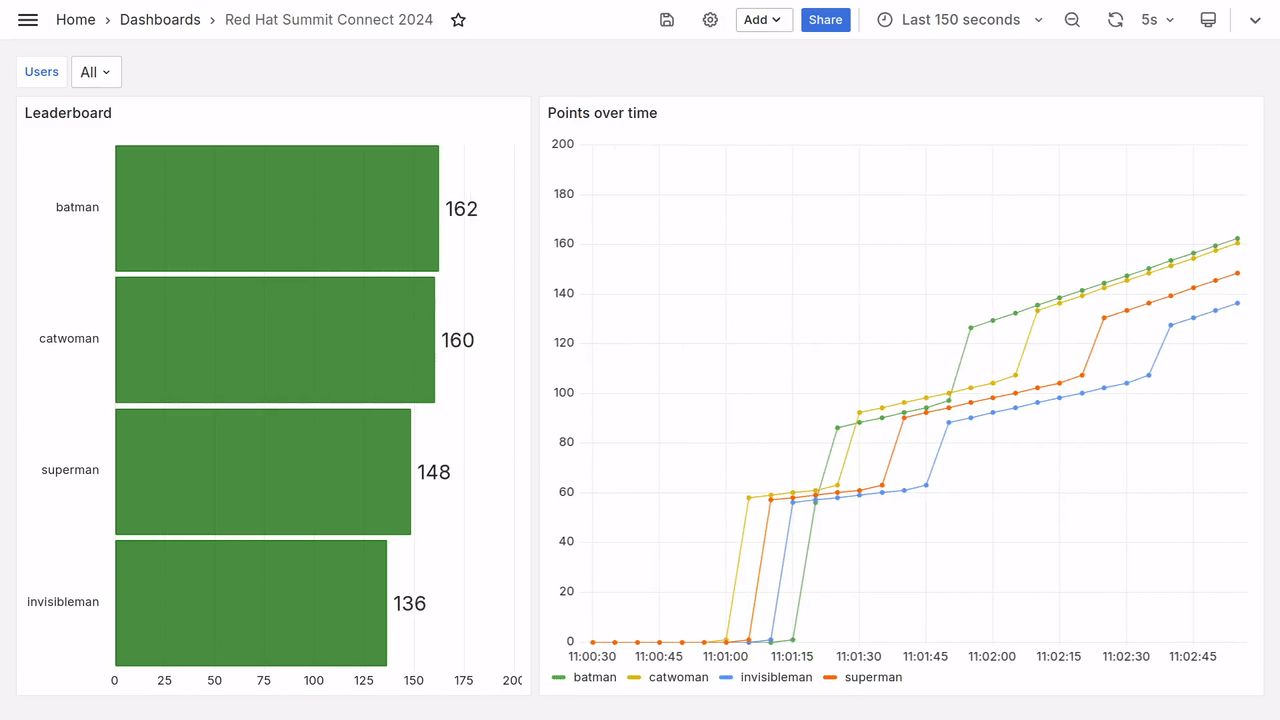
Requêtes Prometheus
Les requêtes Prometheus que j’ai utilisées sont stockées dans le fichier prometheus/recording_rules.yaml.template.
C’est un template qui contient des variables.
Ces variables sont remplacées par leur valeur lors de l’exécution du script run.sh.
Toutes les requêtes sont enregistrées sous la forme de recording rules Prometheus. Elles sont réparties en trois groupes :
- Les requêtes
opencodequest_leaderboard_*représentent l’état de complétude d’un exercice par un utilisateur. - Les requêtes
opencodequest_leaderboard_*_onetime_bonusreprésentent le bonus temps qu’acquiert un utilisateur qui termine un exercice. - Les requêtes
opencodequest_leaderboard_*_lifetime_bonusreprésentent le report à nouveau du bonus temps qu’acquiert un utilisateur qui termine un exercice.
Requêtes opencodequest_leaderboard_*
Les trois requêtes qu’il faut comprendre en premier sont :
opencodequest_leaderboard_hero:prod: état de complétude de l’exercice hero (0 = non terminé, 1 = terminé)opencodequest_leaderboard_villain:prod: état de complétude de l’exercice villain (idem)opencodequest_leaderboard_fight:prod: état de complétude de l’exercice fight (idem)
Ces trois requêtes sont conçues sur le même modèle. J’ai pris la première que j’ai légèrement adaptée et formattée pour qu’elle soit plus compréhensible. C’est presque une requète valide. Il faudra juste, avant de l’exécuter, remplacer $EPOCHSECONDS par le timestamp unix de l’heure courante.
sum(
timestamp(
label_replace(up{instance="localhost:9090"}, "user", "superman", "","")
) >= bool ($EPOCHSECONDS + 55)
or
timestamp(
label_replace(up{instance="localhost:9090"}, "user", "catwoman", "","")
) >= bool ($EPOCHSECONDS + 50)
or
timestamp(
label_replace(up{instance="localhost:9090"}, "user", "invisibleman", "","")
) >= bool ($EPOCHSECONDS + 60)
or
timestamp(
label_replace(up{instance="localhost:9090"}, "user", "batman", "","")
) >= bool ($EPOCHSECONDS + 65)
) by (user)
Pour remplacer $EPOCHSECONDS par le timestamp unix de l’heure courante, vous pouvez passer par un here-doc dans votre Shell préféré :
cat << EOF
Requète Prometheus
EOF
Copiez-collez la requète dans la section Explore de Grafana et vous devriez obtenir le graphe suivant.
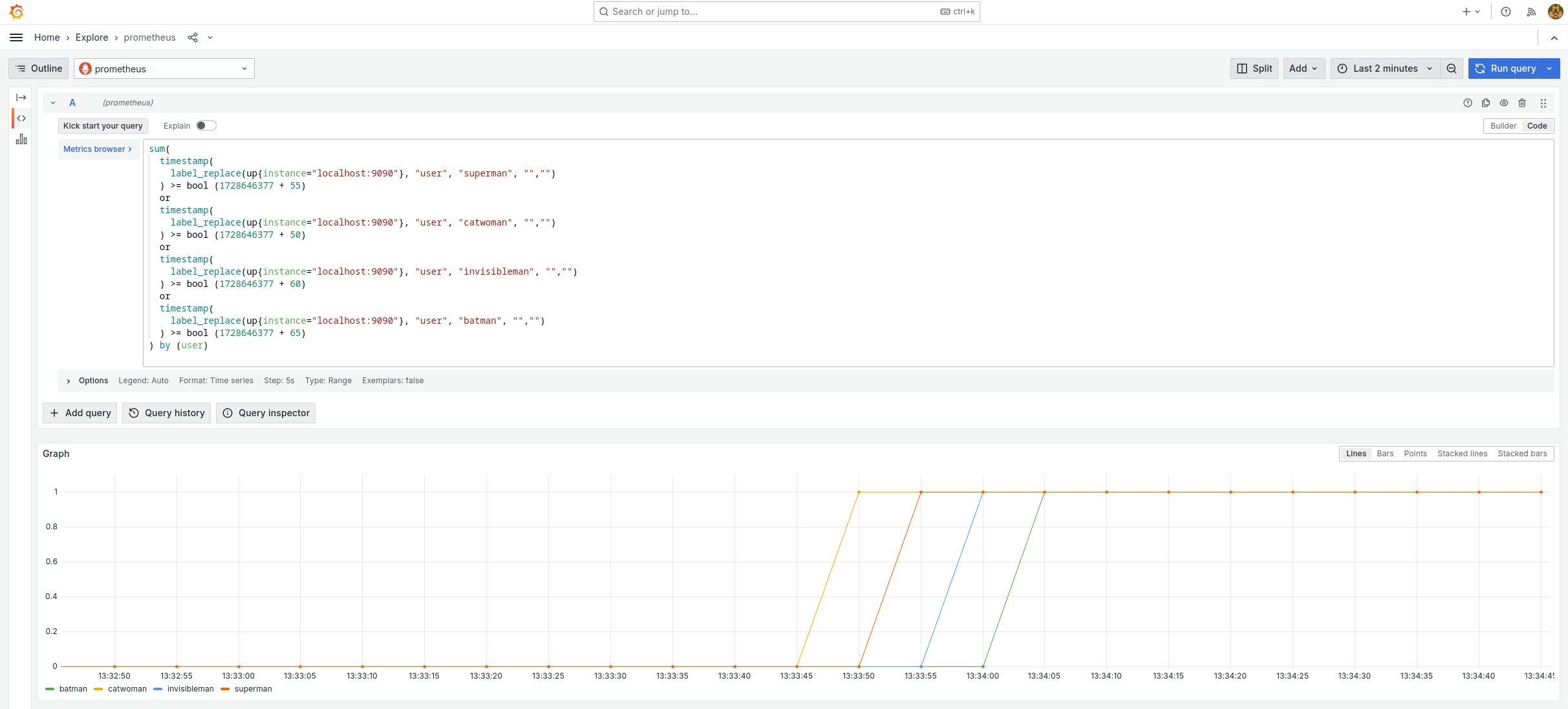
Il faut le lire de la manière suivante (note : 1728646377 = 13:32:57) :
- Superman termine l’exercice hero 50 secondes après le démarrage de l’atelier.
- Catwoman termine l’exercice hero 55 secondes après le démarrage de l’atelier.
- Invisible Man termine l’exercice hero 60 secondes après le démarrage de l’atelier.
- Batman termine l’exercice hero 65 secondes après le démarrage de l’atelier.
Cette requête fonctionne de la manière suivante :
up{instance="localhost:9090"}est une time serie qui retourne toujours 1, accompagnée de plein de labels qui nous sont inutiles pour notre besoin.label_replace(TIMESERIE, "user", "superman", "","")ajoute l’étiquette user=superman à la time serie.timestamp(TIMESERIE) >= bool TSretourne 1 pour toute mesure prise après le timestamp TS, 0 sinon.TIMESERIE1 or TIMESERIE2fusionne les deux time series.sum(TIMESERIE) by (user)supprime toutes les étiquettes, saufuser. J’aurais pu utilisermin,max, etc. à la place desumcar je n’ai qu’une seule timeserie par valeur de user.
Le résultat de ces trois requêtes est stocké dans Prometheus sous la forme de time series grace aux recording rules qui les définissent.
Elles représentent le jeu de données de test qui me sert à valider le bon fonctionnement du Leaderboard. Dans l’environnement Open Code Quest, elles seront remplacées par des vraies métriques en provenance des clusters OpenShift.
Requêtes opencodequest_leaderboard_*_onetime_bonus
Les requêtes suivantes calculent un bonus temps pour les utilisateurs qui terminent un exercice. Plus l’utilisateur termine tôt l’exercice (par rapport à l’heure de fin prévue), plus le bonus est conséquent. Et inversement, plus l’utilisateur est en retard par rapport à l’heure de fin prévue, moins le bonus est conséquent.
opencodequest_leaderboard_hero_onetime_bonus:prodreprésente le bonus temps affecté à l’utilisateur qui termine l’exercice hero.opencodequest_leaderboard_villain_onetime_bonus:prodreprésente le bonus temps affecté à l’utilisateur qui termine l’exercice villain.opencodequest_leaderboard_fight_onetime_bonus:prodreprésente le bonus temps affecté à l’utilisateur qui termine l’exercice fight.
Ces trois requêtes sont conçues sur le même modèle. Ça peut paraître complexe de prime abord mais en fait pas tant que ça.
(increase(opencodequest_leaderboard_hero:prod[10s]) >= bool 0.5)
*
(
55
+
sum(
(
${TS_EXERCISE_HERO}
-
timestamp(
label_replace(up{instance="localhost:9090"}, "user", "superman", "","")
or
label_replace(up{instance="localhost:9090"}, "user", "invisibleman", "","")
or
label_replace(up{instance="localhost:9090"}, "user", "catwoman", "","")
or
label_replace(up{instance="localhost:9090"}, "user", "batman", "","")
)
) / 5
) by (user)
)
Pour bien comprendre comment fonctionne cette requête, je vous propose de la scinder en deux : la partie increase(...) d’un coté et le reste de l’autre.
On superpose tout ça avec la requête précédente et ça donne la figure suivante.
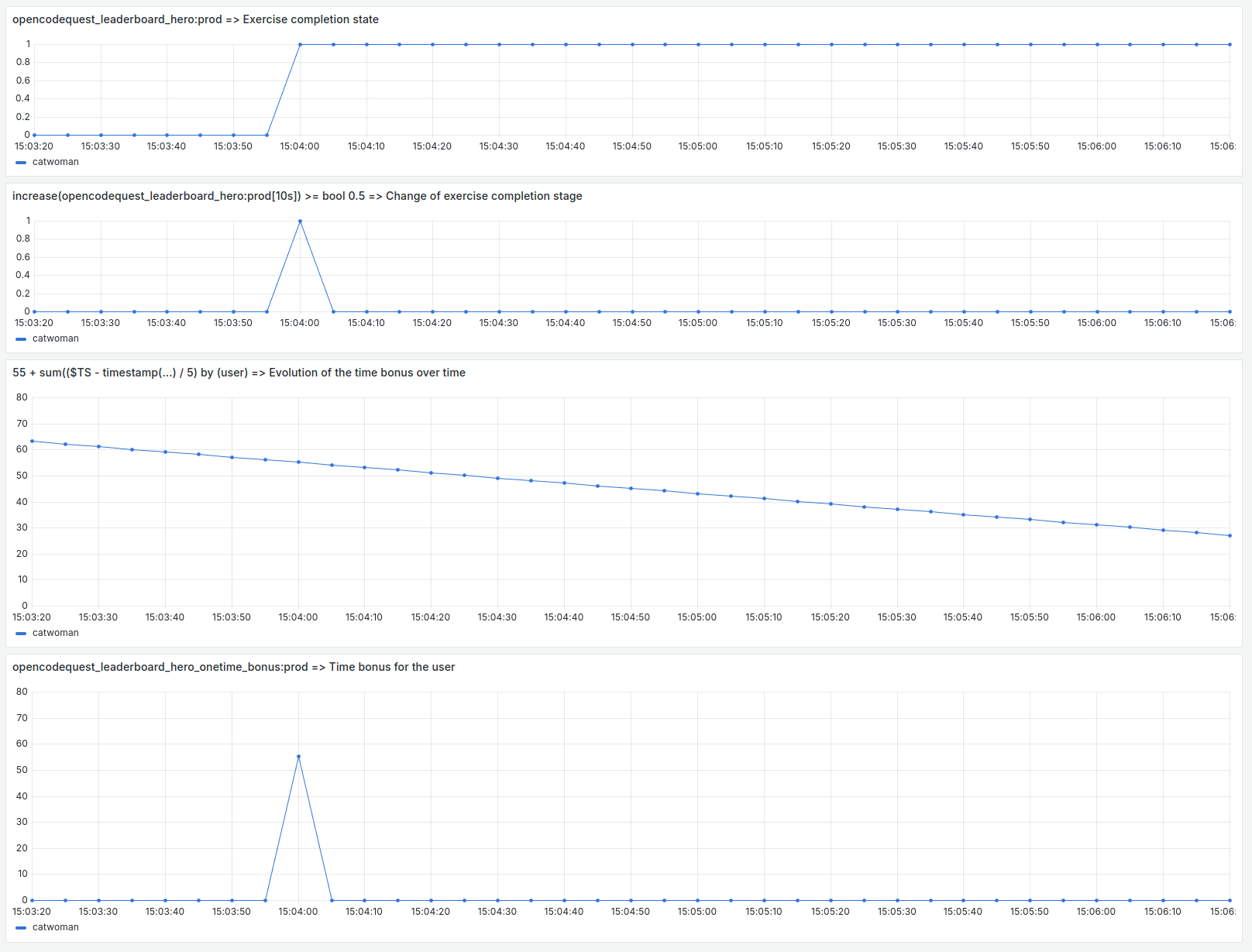
De haut en bas, on peut observer :
- La requête
opencodequest_leaderboard_hero:prod. Elle représente l’état de complétude de l’exercice. - La partie
increase(opencodequest_leaderboard_hero:prod[10s]) >= bool 0.5détecte les changements d’état de la requête précédente. - La partie
55 + sum(($TS - timestamp(...) / 5) by (user)représente l’évolution du bonus temps au cours du temps. Le terme 55 est le bonus nominal de l’exercice et le diviseur 5 permet de faire varier le bonus d’une unité toutes les 5 secondes. - Le tout est l’application du bonus temps au moment où l’utilisateur termine l’exercice.
Requêtes opencodequest_leaderboard_*_lifetime_bonus
Les requêtes suivantes reportent le bonus temps de mesures en mesures jusqu’à la fin de l’atelier.
opencodequest_leaderboard_hero_lifetime_bonus:prodreprésente le report à nouveau du bonus temps affecté à l’utilisateur qui termine l’exercice hero.opencodequest_leaderboard_villain_lifetime_bonus:prodreprésente le report à nouveau du bonus temps affecté à l’utilisateur qui termine l’exercice villain.opencodequest_leaderboard_fight_lifetime_bonus:prodreprésente le report à nouveau du bonus temps affecté à l’utilisateur qui termine l’exercice fight.
Ces trois requêtes sont conçues sur le même modèle :
sum_over_time(opencodequest_leaderboard_hero_onetime_bonus:prod[1h])
La fonction sum_over_time(TIMESERIE) effectue la somme des valeurs de la time serie au cours du temps.
On peut le voir comme l’intégrale de la time serie.
La figure suivante présente le fonctionnement de cette requête de manière plus parlante.
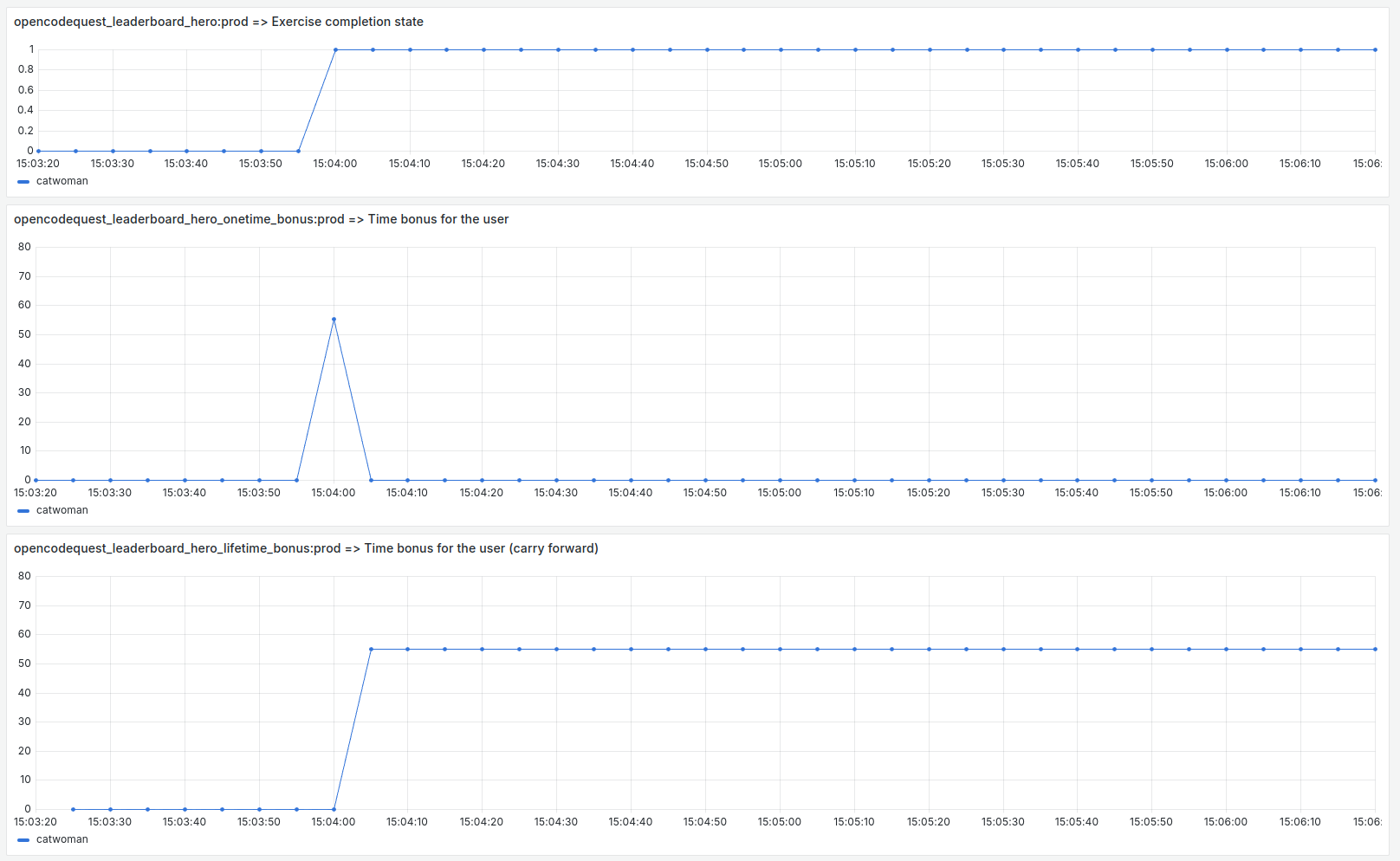
De haut en bas, on peut observer :
- La requête
opencodequest_leaderboard_hero:prod. Elle représente l’état de complétude de l’exercice. - La requête
opencodequest_leaderboard_hero_onetime_bonus:prod. Elle représente l’application du bonus temps au moment où l’utilisateur termine l’exercice. - Le résultat est le report à nouveau du bonus temps depuis le moment où l’utilisateur termine l’exercice.
Note: on voit un décalage d’une unité de temps entre la dernière requête et les deux premières Je pense que c’est une conséquence des dépendances entre les recording rules.
La requête finale
La requête finale qui détermine les points des utilisateurs est la somme de 6 composantes :
- Le bonus temps de l’exercice hero (reporté)
- L’accélérateur activé à la fin de l’exercice hero
- Le bonus temps de l’exercice villain (reporté)
- L’accélérateur activé à la fin de l’exercice villain
- Le bonus temps de l’exercice fight (reporté)
- L’accélérateur activé à la fin de l’exercice fight
Dans le dialecte utilisé par Prometheus, cela s’écrit de la façon suivante :
opencodequest_leaderboard_hero_lifetime_bonus:prod
+ sum_over_time(opencodequest_leaderboard_hero:prod[1h])
+ opencodequest_leaderboard_villain_lifetime_bonus:prod
+ sum_over_time(opencodequest_leaderboard_villain:prod[1h])
+ opencodequest_leaderboard_fight_lifetime_bonus:prod
+ sum_over_time(opencodequest_leaderboard_fight:prod[1h])
Les bonus temps ont été décrit dans la section précédente. Il ne me reste donc qu’à vous expliquer le fonctionnement de l’accélérateur.
Les time series opencodequest_leaderboard_{hero,villain,fight}:prod sont l’état de complétude de l’exercice (valeur binaire : 0 ou 1).
Pour obtenir une rampe, il faut prendre son intégrale.
J’utilise donc la fonction sum_over_time(TIMESERIE) à cet effet.
Pour corser le jeu, on pourrait imaginer changer la pente de la rampe via un coefficient multiplicateur mais j’ai jugé que ce n’était pas nécessaire.
En effet, les 3 accélérateurs s’additionnent déjà, ce qui fait que l’utilisateur gagne 1 point toutes les 5 minutes qui passent après l’exercice hero, 2 points après l’exercice villain et 3 points après l’exercice fight.
La figure suivante présente les 6 composantes de requête Prometheus permettant de calculer les points de l’utilisateur.
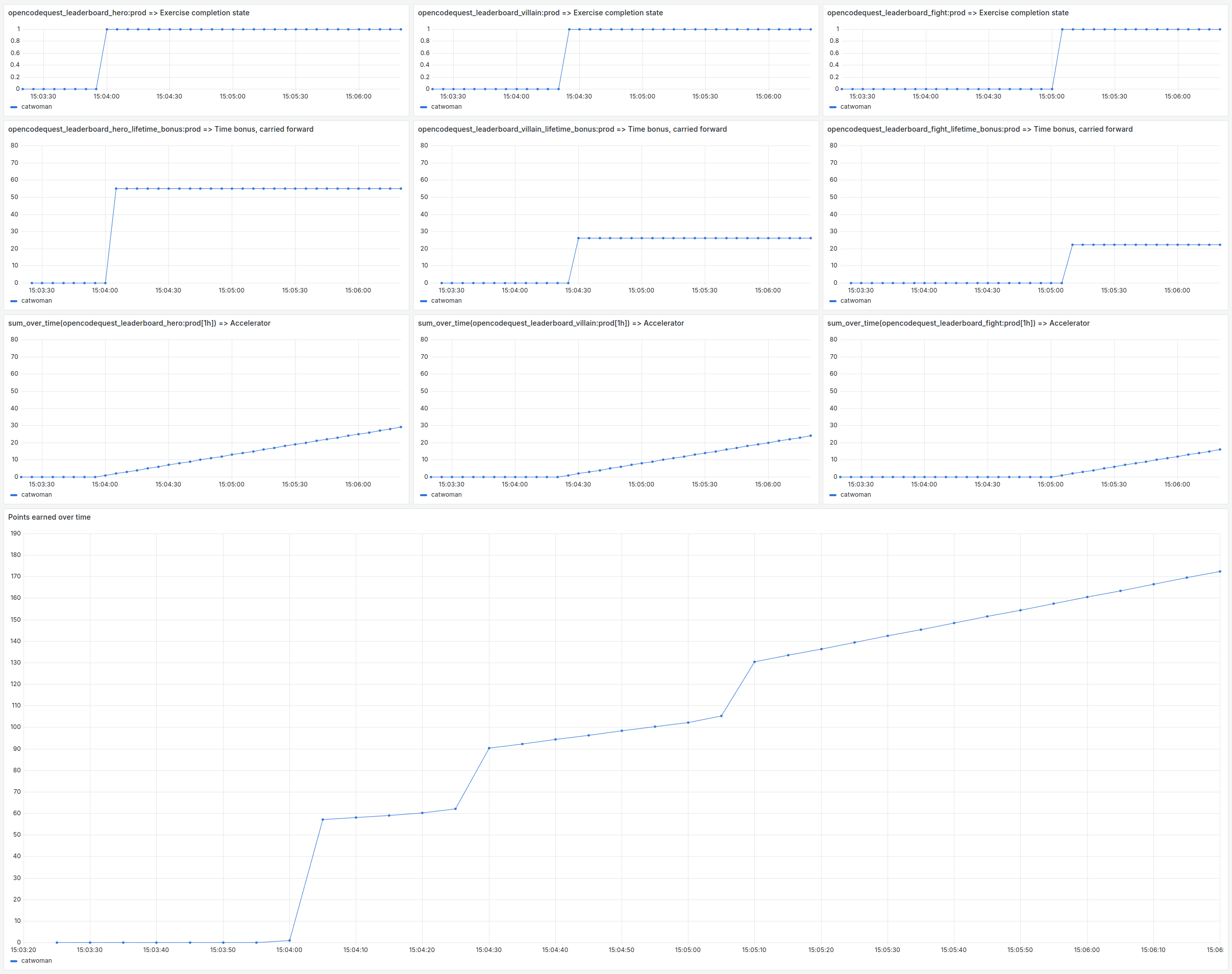
Recording Rules
Les requêtes opencodequest_leaderboard_* s’appuient sur la fonction increase et les requêtes opencodequest_leaderboard_*_lifetime_bonus s’appuient sur la fonction sum_over_time.
Ces deux fonctions Prometheus ont une contrainte : on ne peut les appliquer que sur un range vector (c’est la syntaxe timeserie[range] que vous avez aperçue dans les exemples ci-dessus).
Et un range vector ne peut pas être le résultat d’un calcul.
C’est à dire que la requête suivante est valide :
// OK
sum_over_time(
opencodequest_leaderboard_hero:prod[1h]
)
Mais celles-ci ne le sont pas :
// parse error: ranges only allowed for vector selectors
sum_over_time(
(1 + opencodequest_leaderboard_hero:prod)[1h]
)
// parse error: binary expression must contain only scalar and instant vector types
sum_over_time(
1 + opencodequest_leaderboard_hero:prod[1h]
)
Cela signifie qu’il n’est pas possible de construire une méga-requête qui calculerait le score de tous les participants au cours du temps. Il faut donc, à chaque utilisation d’une de ces fonctions nécessitant un range vector, passer par une recording rule pour matérialiser le résultat du calcul dans une time serie nommée. Et comme nos requêtes dépendent les unes des autres, il faut les placer dans des groupes de recording rule différents.
C’est pour cette raison que vous retrouverez dans le fichier prometheus/recording_rules.yaml.template, trois groupes de recording rules :
opencodequest_basepour le jeu de données de test (qui n’existe que dans le banc d’essai).opencodequest_step1pour les requêtesopencodequest_leaderboard_*_onetime_bonus.opencodequest_step2pour les requêtesopencodequest_leaderboard_*_lifetime_bonus.
Et vous verrez dans l’article suivant que les recording rules dans une configuration Red Hat Advanced Cluster Management ont quelques subtilités…
Création du tableau de bord Grafana
Une fois toutes les requêtes Prometheus mises au point, la création du tableau de bord Grafana est relativement simple :
- Créer deux variables : env (l’environnement des participants sur lequel calculer le score) et user (la liste des utilisateurs à inclure dans le leaderboard).
- Ajouter deux visualisations : une pour le classement instantané et une pour la progression des points au cours du temps.
La variable user est multi-valuée (on peut sélectionner tous les utilisateurs ou décocher les utilisateurs qu’on ne veut pas voir… comme ceux ayant servi à la recette la veille !) et les valeurs possibles sont extraites des labels d’une time serie Prometheus (peu importe laquelle, tant que tous les utilisateurs sont représentés).
La variable env a trois valeurs possibles (“dev”, “preprod” ou “prod”) mais on ne peut sélectionner qu’une valeur à la fois.
Ces deux variables s’utilisent ensuite dans la requète du Leaderboard de la manière suivante :
max(
opencodequest_leaderboard_hero_lifetime_bonus:${env:text}{user=~"${user:regex}"}
+ sum_over_time(opencodequest_leaderboard_hero:${env:text}{user=~"${user:regex}"}[1h])
+ opencodequest_leaderboard_villain_lifetime_bonus:${env:text}{user=~"${user:regex}"}
+ sum_over_time(opencodequest_leaderboard_villain:${env:text}{user=~"${user:regex}"}[1h])
+ opencodequest_leaderboard_fight_lifetime_bonus:${env:text}{user=~"${user:regex}"}
+ sum_over_time(opencodequest_leaderboard_fight:${env:text}{user=~"${user:regex}"}[1h])
) by (user)
La syntaxe ${user:regex} permet à Grafana de remplacer user=~"${user:regex}" par user=~"(batman|catwoman|invisibleman|superman)" lorsque plusieurs valeurs sont sélectionnées dans la liste déroulante.
Visualisation du classement instantané
Pour montrer le classement instantané, j’ai utilisé la visualisation Bar Chart avec une transformation de type Sort by sur le champ Value.
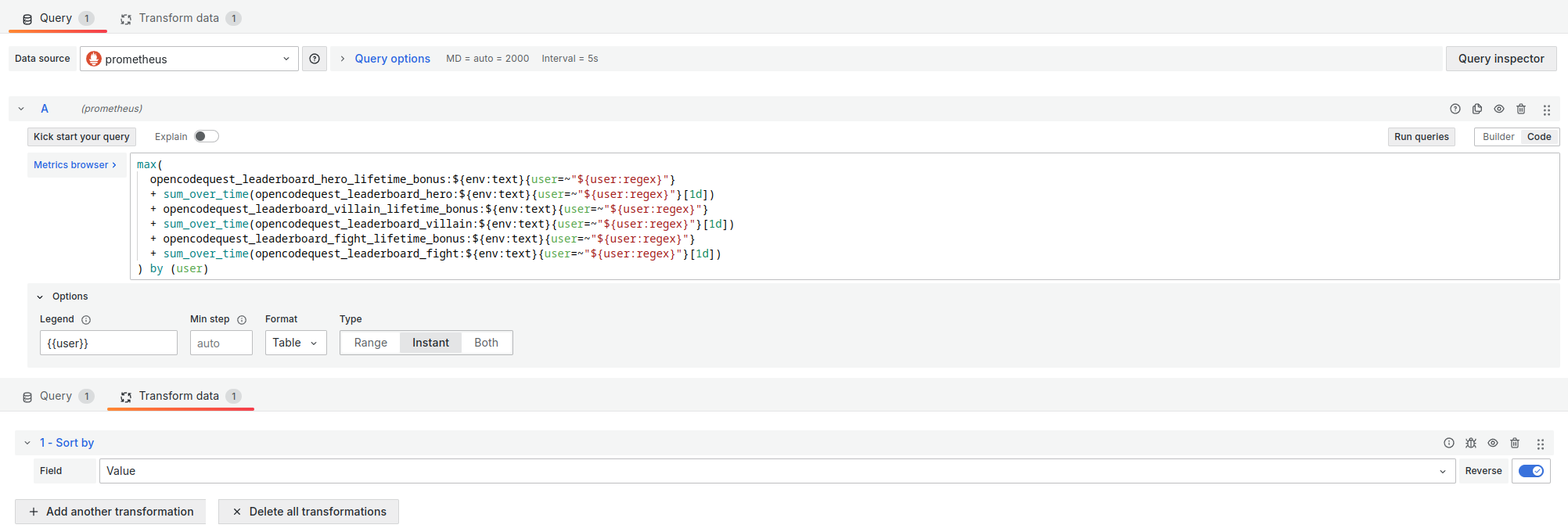
Les paramètres importants de cette visualisation sont :
- Format :
Table - Type :
Instant - Legend :
{{user}}(pour afficher le nom du participant en face de son score)
Visualisation des points au cours du temps
Pour suivre la progression des points au cours du temps, j’ai opté pour la visualisation Time series.
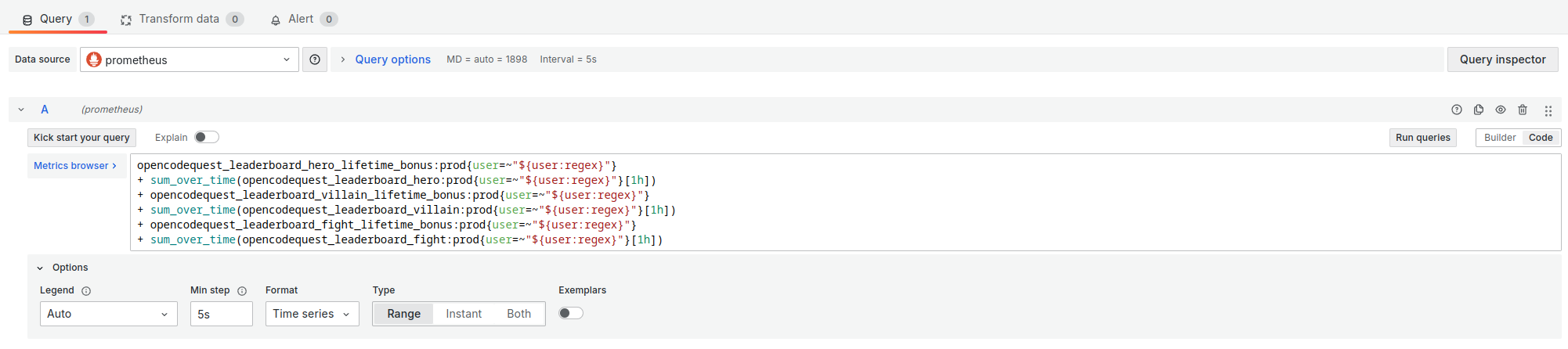
Les paramètres importants de cette visualisation sont :
- Format :
Time series - Type :
Range - Min step :
5slors de la mise au point sur le banc d’essai et5men vrai.
Résultat
Le tableau de bord utilisé le jour de l’Open Code Quest était peu ou prou ce que l’on voit sur la figure 5 (le gif animé) :
- Le classement instanané, projeté par moment sur le vidéo projecteur pour annoncer les scores intermédiaires.
- La progression des points au cours du temps, affichée sur un deuxième écran pour garder un oeil sur la compétition.
Vous retrouverez tous les tableaux de bord Grafana présentés ici dans le dossier grafana.
Le jour de l’Open Code Quest
Le jour de l’Open Code Quest, le Leaderboard a bien fonctionné et nous a permis de déterminer les 30 participants les plus rapides. Ils sont montés sur scène pour recevoir une récompense.
Quant à la question qui est sur toutes les lèvres : est-ce qu’il y a eu de la baston entre super héros pour le podium ? La réponse est un grand OUI ! Et il y a eu du frisson lors de l’annonce des résultats…
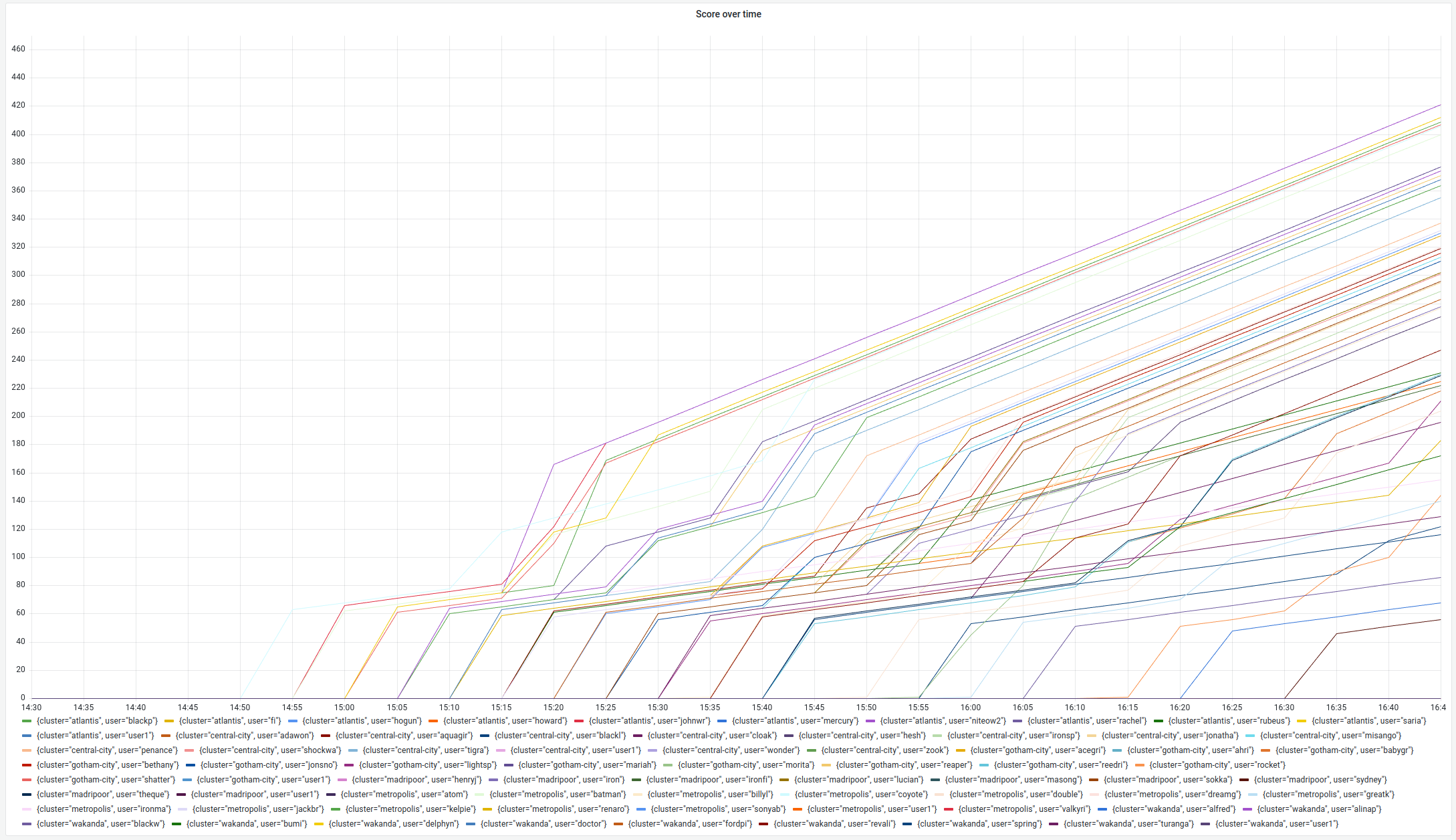
Observez toutes ces courbes qui se croisent, tous ces super-héros en compétition pour la première place !
Conclusion
En conclusion, l’Open Code Quest a été une expérience aussi stimulante pour les participants que pour moi en tant qu’organisateur. Ce projet a non seulement mis en lumière des technologies comme Quarkus, OpenShift et le modèle Granite d’IBM, mais il a également démontré à quel point des outils comme Prometheus et Grafana peuvent être utilisés de manière créative pour répondre à des problématiques bien concrètes.
Concevoir le Leaderboard, bien que complexe, a ajouté une dimension compétitive motivante à l’atelier. Le jour J, voir les participants rivaliser de rapidité tout en explorant les solutions Red Hat a été incroyablement gratifiant.
Et pour savoir comment j’ai implémenté ce Leaderboard dans une architecture multi-cluster avec Red Hat ACM, c’est par ici : Dans les coulisses de l'Open Code Quest : comment j'ai implémenté le Leaderboard dans Red Hat Advanced Cluster Management .