Construction d'images de conteneur multi-architecture avec OpenShift, Buildah et Tekton dans le cloud AWS
En 2022, j’ai écrit un article sur ce sujet intitulé Build multi-architecture container images with Kubernetes, Buildah, Tekton and Qemu . L’article relatait la configuration que j’avais mise en place pour mes projets personnels. Il a même un peu débordé de sa vocation initiale puisqu’il a également été utilisé par plusieurs collègues chez Red Hat qui avaient le même besoin. Si la configuration décrite dans ce précédent article est toujours d’actualité, l’approche est un peu datée. Avec la disponibilité grandissante des serveurs ARM dans le Cloud, j’ai revisité le sujet de la construction d’image de conteneurs multi-architecture en utilisant le cloud AWS.
Cas d’usage
Dans cet article, j’explore la construction d’image de conteneurs multi-architecture au travers de trois cas d’usage :
- Construction d’une image depuis un Dockerfile / Containerfile. Une image de base multi-architecture est disponible dans une registry et le Dockerfile / Containerfile vient appliquer une série de modifications à cette image. L’image résultante est également multi-architecture.
- Construction d’une application NodeJS.
Une application NodeJS est construite (
npm installde ses dépendances, mais ça peut être plus complexe). L’application construite est déposée via un Containerfile sur une image de base multi-architecture. L’image résultante est également multi-architecture. - Construction d’une application Quarkus.
Une application Quarkus est construite (via la commande
mvn package). L’application construite est déposée via un Containerfile sur une image de base multi-architecture. L’image résultante est également multi-architecture.
Pour démontrer la faisabilité de la construction d’image de conteneurs multi-architecture, je construis des images de conteneurs pour les architectures x86_64 et arm64. Mais l’approche est généralisable à toute architecture supportée par OpenShift.
Le code illustrant ces trois cas d’usage et leur pipelines Tekton associés sont dans ce dépôt Git.
Vue d’ensemble
Pour mettre en oeuvre ces trois cas d’usage, je vais mettre en place :
- Un cluster OpenShift composé de Compute nodes x86_64 et arm64.
- Un pipeline Tekton orchestrant les constuctions d’image sur ces deux noeuds et combinant les images résultantes en un manifeste qui est ensuite déposé sur la registry quay.io.
- Du stockage persistant de type EFS pour stocker le code source, les artefacts et les images de conteneurs avant leur envoi sur la registry quay.io.
Si le précédent article ciblait les plateformes Kubernetes vanilla, dans celui-ci je me concentre sur OpenShift. J’utiliserai également OpenShift Pipelines, la distribution Tekton de Red Hat plutôt que le Tekton upstream.
Dans les pipelines Tekton, j’utilise Buildah pour construire et pousser sur la registry les images de conteneurs.

Déploiement d’OpenShift sur AWS en mode multi-architecture
Procédure d’installation
Dans la suite de cet article, je déploie OpenShift 4.15 sur AWS mais la démarche reste sensiblement la même sur les autres environnements Cloud (Azure, GCP, etc.) Je pars d’un environnement AWS déjà préparé pour OpenShift.
Pour limiter les coûts, je déploie un cluster OpenShift composé du strict minimum :
- 1 Control Plane node x86_64
- 1 Compute node x86_64
- 1 Compute node arm64
Dans la documentation OpenShift 4.15, les machines ARM64 testées sont :
- c6g.* avec un coût de 0,0405 $ à 2,592 $ par heure (compute optimized)
- m6g.* avec un coût de 0,045 $ à 2,88 $ par heure (general purpose)
Au final, je choisis les types de machine suivants :
- m5a.2xlarge pour le Control Plane node et le Compute node x86_64
- m6g.2xlarge pour le Compute node arm64
La procédure d’installation est la suivante :
- Déploiement d’un cluster OpenShift de type Single Node (SNO) pour avoir le Control Plane node
- Ajout du Compute node x86_64 a posteriori
- Ajout du Compute node arm64 a posteriori
Je détaille les points clés de cette installation mais pensez à bien lire la documentation OpenShift 4.15 avant !
Pré-requis
L’installation d’un cluster multi-architecture passe par une version spécifique de la CLI openshift-install.
Télécharger la CLI OpenShift multi architecture.
curl -sfL https://mirror.openshift.com/pub/openshift-v4/multi/clients/ocp/4.15.1/amd64/openshift-install-linux.tar.gz | sudo tar -zx -C /usr/local/bin openshift-install
curl -sfL https://mirror.openshift.com/pub/openshift-v4/multi/clients/ocp/4.15.1/amd64/openshift-client-linux-4.15.1.tar.gz | sudo tar -zx -C /usr/local/bin oc kubectl
Création du Control Plane node
Créer le fichier install-config.yaml. Les zones surlignées sont les points importants du fichier.
additionalTrustBundlePolicy: Proxyonly
apiVersion: v1
baseDomain: aws.itix.cloud
compute:
- architecture: amd64
hyperthreading: Enabled
name: worker
platform:
aws:
type: m5a.2xlarge
zones:
- eu-west-3a
- eu-west-3b
- eu-west-3c
replicas: 0
controlPlane:
architecture: amd64
hyperthreading: Enabled
name: master
platform:
aws:
rootVolume:
iops: 4000
size: 500
type: io1
type: m5a.2xlarge
zones:
- eu-west-3c
replicas: 1
metadata:
creationTimestamp: null
name: build-multiarch
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineNetwork:
- cidr: 10.0.0.0/16
networkType: OVNKubernetes
serviceNetwork:
- 172.30.0.0/16
platform:
aws:
region: eu-west-3
publish: External
pullSecret: 'REDACTED'
sshKey: |
REDACTED J’ai choisis de laisser la déclaration des Compute nodes mais avec un replicas à 0 car cela simplifie l’instanciation du Compute node x86_64 par la suite.
Générer les manifests d’installation.
openshift-install create manifests --dir .
Comme la documentation OpenShift 4.15 indique que le Cluster Samples Operator n’est pas compatible multi-architecture, nous devons le désactiver via les cluster capabilities.
Editer le fichier manifests/cvo-overrides.yaml et ajouter la section additionalEnabledCapabilities. Ne faites pas un copier-coller du fichier complet ci-dessous car le clusterID est spécifique à votre installation !
apiVersion: config.openshift.io/v1
kind: ClusterVersion
metadata:
namespace: openshift-cluster-version
name: version
spec:
channel: stable-4.15
clusterID: REDACTED
baselineCapabilitySet: None
additionalEnabledCapabilities:
- marketplace
- MachineAPI
- Console
- Insights
- Storage
- CSISnapshot
- NodeTuning
- ImageRegistry
- OperatorLifecycleManager
- Build
- DeploymentConfigDémarrer l’installation du cluster sur AWS.
openshift-install create cluster --dir . --log-level=info
Si tout se passe bien, une trentaine de minutes plus tard, vous devriez avoir quelque chose comme ça :
INFO Consuming Common Manifests from target directory
INFO Consuming Master Machines from target directory
INFO Consuming Openshift Manifests from target directory
INFO Consuming Worker Machines from target directory
INFO Consuming OpenShift Install (Manifests) from target directory
INFO Credentials loaded from the "default" profile in file "/home/nmasse/.aws/credentials"
INFO Creating infrastructure resources...
INFO Waiting up to 20m0s (until 1:15PM CET) for the Kubernetes API at https://api.build-multiarch.aws.itix.cloud:6443...
INFO API v1.28.6+6216ea1 up
INFO Waiting up to 30m0s (until 1:28PM CET) for bootstrapping to complete...
INFO Destroying the bootstrap resources...
INFO Waiting up to 40m0s (until 1:52PM CET) for the cluster at https://api.build-multiarch.aws.itix.cloud:6443 to initialize...
INFO Waiting up to 30m0s (until 1:50PM CET) to ensure each cluster operator has finished progressing...
INFO All cluster operators have completed progressing
INFO Checking to see if there is a route at openshift-console/console...
INFO Install complete!
INFO To access the cluster as the system:admin user when using 'oc', run 'export KUBECONFIG=./auth/kubeconfig'
INFO Access the OpenShift web-console here: https://console-openshift-console.apps.build-multiarch.aws.itix.cloud
INFO Login to the console with user: "kubeadmin", and password: "REDACTED"
INFO Time elapsed: 30m21s
Définir la variable KUBECONFIG pour accéder au cluster.
export KUBECONFIG=$PWD/auth/kubeconfig
Ajout du Compute node x86_64
Comme le fichier install-config.yaml contenait la définition des Compute nodes mais avec le replicas à 0, les MachineSet ont bien été générés et sont presque prêt à servir.
$ oc -n openshift-machine-api get MachineSet
NAME DESIRED CURRENT READY AVAILABLE AGE
build-multiarch-tw9w9-worker-eu-west-3a 0 0 67m
build-multiarch-tw9w9-worker-eu-west-3b 0 0 67m
build-multiarch-tw9w9-worker-eu-west-3c 0 0 67m
Ajouter aux futurs Compute nodes l’étiquette node-role.kubernetes.io/worker.
for name in $(oc -n openshift-machine-api get MachineSet -o name); do
oc -n openshift-machine-api patch "$name" --type=json -p '[{"op":"add","path":"/spec/template/spec/metadata/labels","value":{"node-role.kubernetes.io/worker":""}}]'
done
Ajouter un Compute node dans la zone eu-west-3a.
oc -n openshift-machine-api scale machineset build-multiarch-tw9w9-worker-eu-west-3a --replicas=1
Ajout du Compute node arm64
La documentation OpenShift 4.15 recense les vérifications à effectuer avant de pouvoir ajouter au cluster un noeud d’une autre architecture.
$ oc adm release info -o jsonpath="{ .metadata.metadata}"
{"release.openshift.io/architecture":"multi","url":"https://access.redhat.com/errata/RHSA-2024:1210"}
$ oc get configmap/coreos-bootimages -n openshift-machine-config-operator -o jsonpath='{.data.stream}' | jq -r '.architectures.aarch64.images.aws.regions."eu-west-3".image'
ami-0eab6a7956a66deda
Ajouter les MachineSet ARM64 au cluster. Ici, l’architecture ARM64 s’appelle “aarch64”.
ARCH="aarch64" # x86_64 or aarch64
AWS_REGION="eu-west-3"
AWS_AZ=("a" "b" "c")
AWS_INSTANCE_TYPE="m6g.2xlarge" # Must match $ARCH!
AMI_ID="$(oc get configmap/coreos-bootimages -n openshift-machine-config-operator -o jsonpath='{.data.stream}' | jq -r ".architectures.$ARCH.images.aws.regions.\"$AWS_REGION\".image")"
INFRASTRUCTURE_NAME="$(oc get -o jsonpath='{.status.infrastructureName}' infrastructure cluster)"
for az in "${AWS_AZ[@]}"; do
oc apply -f - <<EOF
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
name: $INFRASTRUCTURE_NAME-$ARCH-worker-$AWS_REGION$az
namespace: openshift-machine-api
labels:
machine.openshift.io/cluster-api-cluster: $INFRASTRUCTURE_NAME
spec:
replicas: 0
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: $INFRASTRUCTURE_NAME
machine.openshift.io/cluster-api-machineset: $INFRASTRUCTURE_NAME-$ARCH-worker-$AWS_REGION$az
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: $INFRASTRUCTURE_NAME
machine.openshift.io/cluster-api-machine-role: worker
machine.openshift.io/cluster-api-machine-type: worker
machine.openshift.io/cluster-api-machineset: $INFRASTRUCTURE_NAME-$ARCH-worker-$AWS_REGION$az
spec:
lifecycleHooks: {}
metadata:
labels:
node-role.kubernetes.io/worker: ''
providerSpec:
value:
userDataSecret:
name: worker-user-data
placement:
availabilityZone: $AWS_REGION$az
region: $AWS_REGION
credentialsSecret:
name: aws-cloud-credentials
instanceType: $AWS_INSTANCE_TYPE
metadata:
creationTimestamp: null
blockDevices:
- ebs:
encrypted: true
iops: 0
kmsKey:
arn: ''
volumeSize: 120
volumeType: gp3
securityGroups:
- filters:
- name: 'tag:Name'
values:
- $INFRASTRUCTURE_NAME-worker-sg
kind: AWSMachineProviderConfig
metadataServiceOptions: {}
tags:
- name: kubernetes.io/cluster/$INFRASTRUCTURE_NAME
value: owned
deviceIndex: 0
ami:
id: $AMI_ID
subnet:
filters:
- name: 'tag:Name'
values:
- $INFRASTRUCTURE_NAME-private-$AWS_REGION$az
apiVersion: machine.openshift.io/v1beta1
iamInstanceProfile:
id: $INFRASTRUCTURE_NAME-worker-profile
EOF
done
Ajouter un Compute node arm64 dans la zone eu-west-3b.
oc -n openshift-machine-api scale machineset build-multiarch-tw9w9-aarch64-worker-eu-west-3b --replicas=1
À ce stade, vous devriez avoir trois noeuds dans votre cluster :
- 1 Control plane node x86_64
- 1 Compute node x86_64
- 1 Compute node arm64
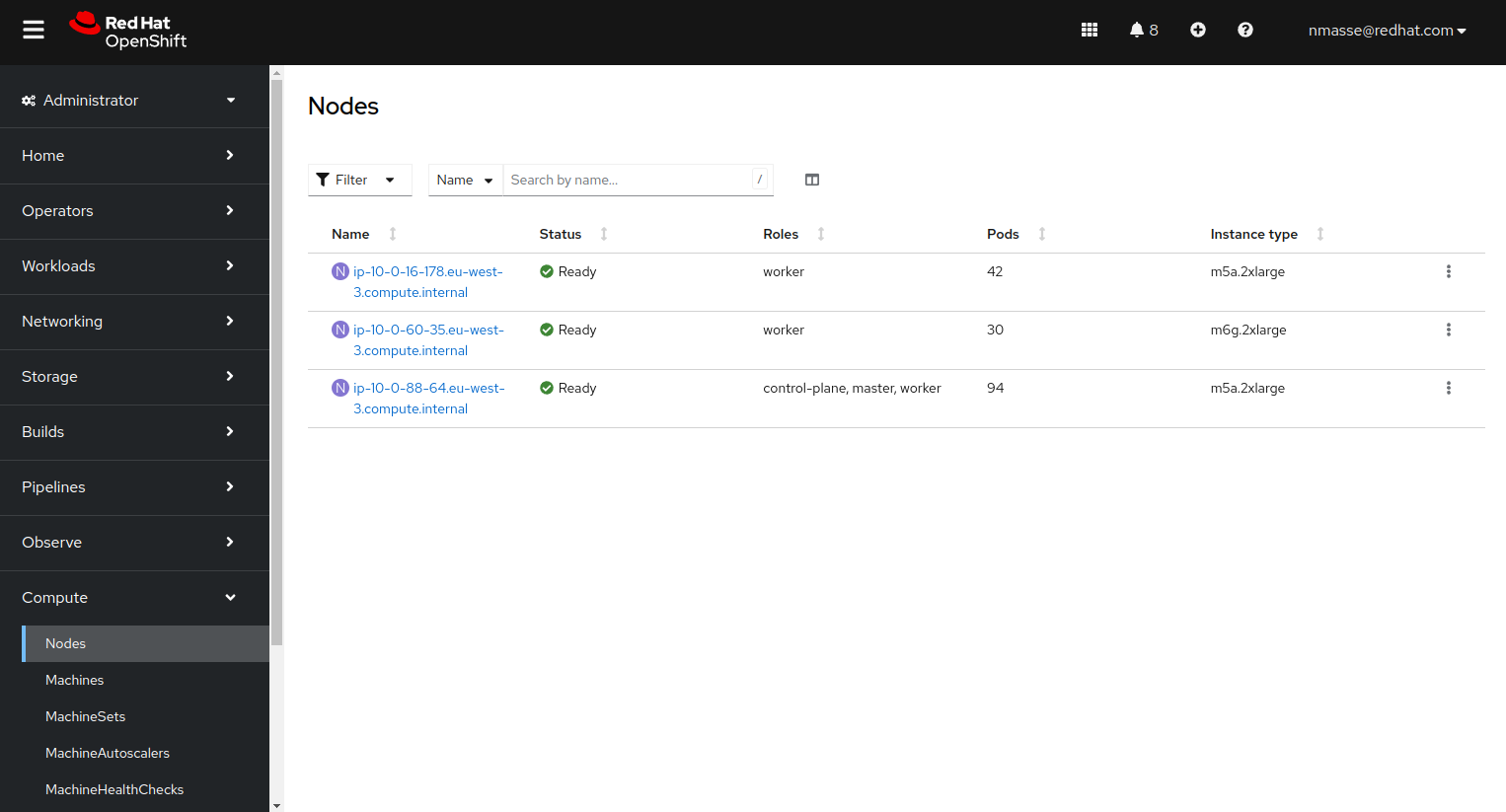
Installation de l’opérateur Tekton
Dans la plateforme OpenShift, l’opérateur Tekton s’appelle OpenShift Pipelines Operator. La documentation explique comment l’installer.
In a nutshell, il suffit de créer la CRD suivante.
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: openshift-pipelines-operator
namespace: openshift-operators
spec:
channel: latest
name: openshift-pipelines-operator-rh
source: redhat-operators
sourceNamespace: openshift-marketplace
Choix d’une technologie de stockage persistant
Les pipelines Tekton qui construisent les images de conteneur ont besoin de stocker des données qui sont utilisées par plusieurs tâches.
Par exemple, une tâche construit l’image x86_64 pendant que en parallèle une tâche construit l’image arm64 et une dernière tâche assemble ces deux images sous la forme d’un manifeste qui sera poussé sur la registry quay.io.
J’avais le choix entre plusieurs technologies de stockage, chacune avec ses avantages et ses inconvénients. J’ai fait le choix d’utiliser AWS EFS mais d’autres technologies auraient été possibles.
- Stockage emptyDir. C’est du stockage éphémère, juste pour la durée de vie du Pod qui exécute la tâche Tekton. Avec ce type de stockage, j’aurais dû utiliser la registry interne OpenShift pour stocker temporairement les images de conteneur avant de les envoyer sur quay.io. Ça m’aurait obligé à faire des macro tâches Tekton (manque de modularité).
- Stockage de type bloc (AWS EBS). En utilisant du stockage de type bloc, je ne peux pas paralléliser les tâches qui ont besoin d’accéder au stockage car l’accès au stockage de type bloc est exclusif : un seul Pod peut le monter à un instant t.
- Stockage de type objet (AWS S3). Le stockage de type objet est bien adapté au stockage des images de manière temporaire en attendant leur envoi sur la registry quay.io. Le désavantage que je lui ai trouvé est qu’il faut un client dans l’image de conteneur (rclone, aws cli, etc.) et ça m’aurait rajouté une étape de copie depuis/vers S3 dans mes tâches Tekton.
J’ai choisi AWS EFS comme stockage persistant pour les pipelines Tekton mais il n’a pas que des avantages.
En particulier, l’utilisation d’AWS EFS depuis Kubernetes peut générer des problème de droits d’accès avec les UIDs aléatoires (SCC restricted) ou arbitraires (SCC anyuid).
L’article How to Solve AWS EFS “Operation Not Permitted” Errors in EKS est un bon résumé du problème.
Initialement, j’ai tenté très naïvement de mettre le répertoire de travail de Buildah (/var/lib/containers) sur un volume AWS EFS. Avec cette configuration, j’ai constaté des lenteurs et les problèmes de droits d’accès mentionnés ci-dessus.
Pour utiliser AWS EFS avec les Pipelines Tekton, j’ai choisi d’aller au plus simple. Plutôt que de mettre le répertoire de travail de Buildah sur un volume AWS EFS, j’ai choisi de recopier manuellement l’image construite par Buildah sur le volume EFS.
Stockage AWS EFS
La documentation OpenShift 4.15 décrit l’installation de l’AWS EFS CSI Driver Operator.
Installer l’AWS EFS CSI Driver Operator.
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: aws-efs-csi-driver-operator
namespace: openshift-cluster-csi-drivers
---
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: aws-efs-csi-driver-operator
namespace: openshift-cluster-csi-drivers
spec:
channel: stable
installPlanApproval: Automatic
name: aws-efs-csi-driver-operator
source: redhat-operators
sourceNamespace: openshift-marketplace
Installer le driver AWS EFS CSI.
apiVersion: operator.openshift.io/v1
kind: ClusterCSIDriver
metadata:
name: efs.csi.aws.com
spec:
managementState: Managed
Créer un volume EFS en suivant les étapes décrites dans la documentation AWS.
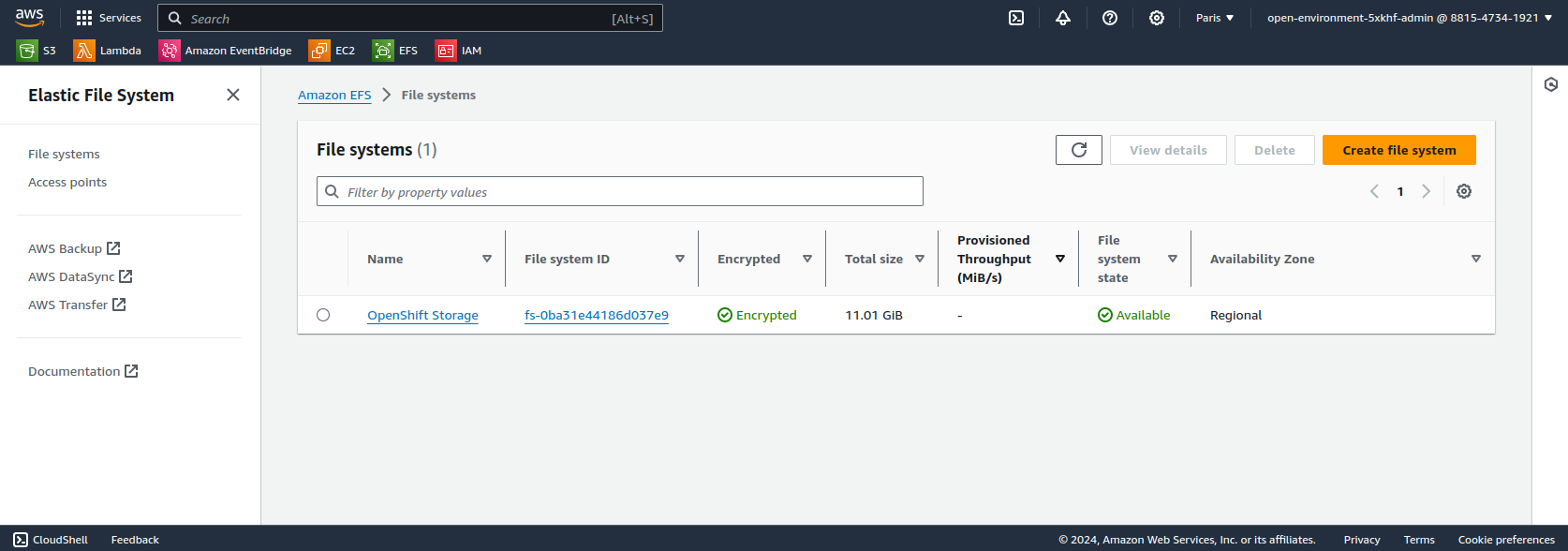
Créer la StorageClass associée au volume EFS.
Le champ fileSystemId correspond à la deuxième colonne de la capture d’écran ci-dessus.
Les champs uid et gid à 0 permettent d’être certain que les Pods qui s’exécutent en root ne verront pas d’incohérences entre leur uid (0) et celui du volume EFS (0 aussi).
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: efs-csi
provisioner: efs.csi.aws.com
parameters:
provisioningMode: efs-ap
fileSystemId: fs-0ba31e44186d037e9
directoryPerms: "700"
basePath: "/pv"
uid: "0"
gid: "0"
En suivant la documentation OpenShift 4.15, modifier le Security Group EFS pour autoriser les noeuds OpenShift à accéder au stockage via le protocole NFS.
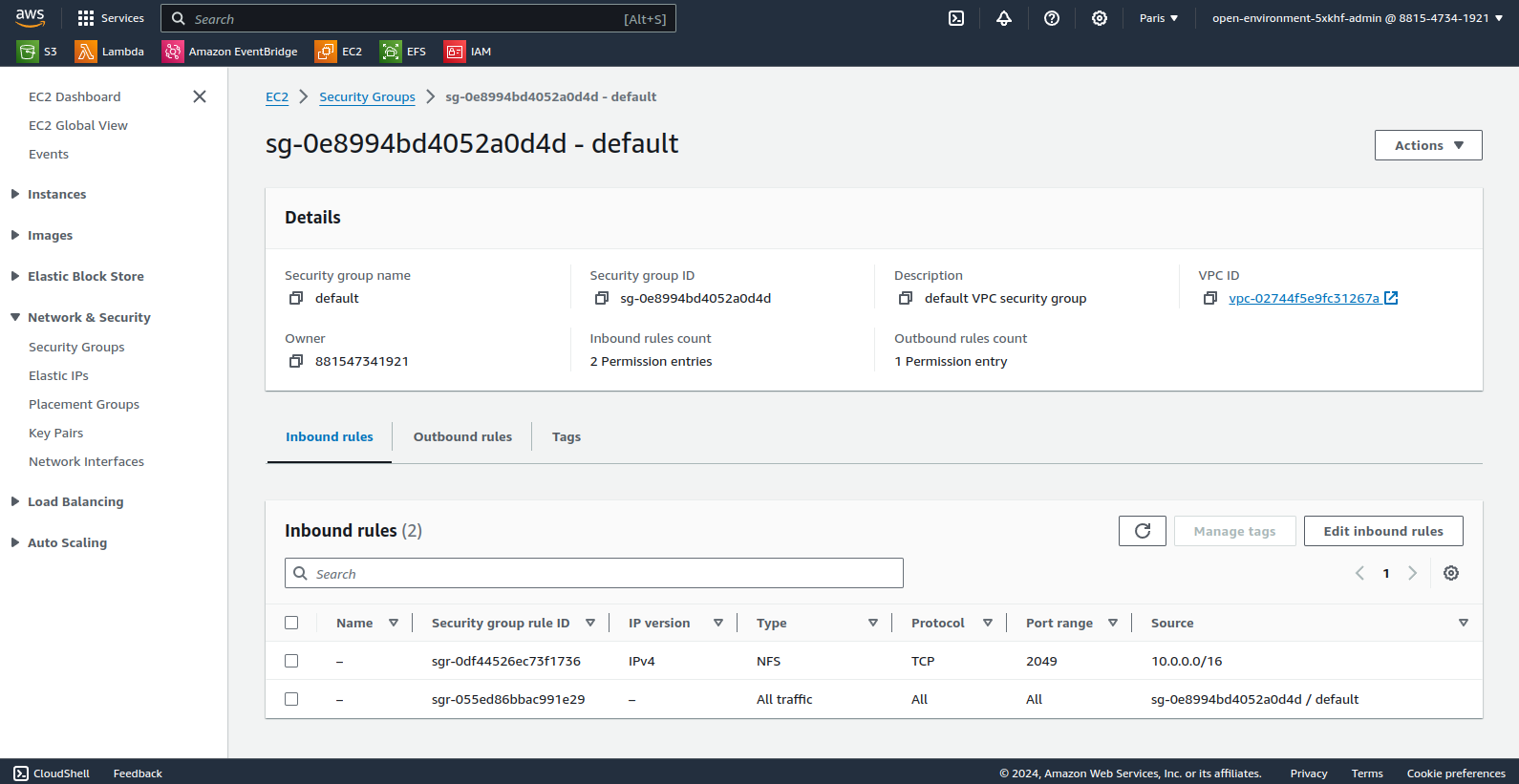
À ce stade, le service AWS EFS est accessible depuis le cluster OpenShift mais il n’est pas encore utilisable par les pipelines Tekton. En effet, l’affinity-assistant de Tekton interdit à un volume persistant RWX d’être monté à deux endroits en même temps (erreur “more than one PersistentVolumeClaim is bound”).
Désactiver l’affinity-assistant dans la configuration Tekton.
oc patch configmap/feature-flags -n openshift-pipelines --type=merge -p '{"data":{"disable-affinity-assistant":"true"}}'
Pipelines Tekton multi-architecture
Dans cette section, je donne brièvement les instructions nécessaire au déploiement des pipelines d’exemple et ensuite je détaille les spécificités de chaque pipeline.
Créer un projet OpenShift.
oc new-project build-multiarch
Créer le Secret contenant votre login et mot de passe quay.io.
oc create secret docker-registry quay-authentication --docker-email=nmasse@redhat.com --docker-username=nmasse --docker-password=REDACTED --docker-server=quay.io
oc annotate secret/quay-authentication tekton.dev/docker-0=https://quay.io
Cloner le dépôt Git tekton-pipeline-multiarch.
git clone https://github.com/nmasse-itix/tekton-pipeline-multiarch
cd tekton-pipeline-multiarch
Déployer les pipelines Tekton.
oc apply -k tekton/
for yaml in examples/*/tekton/pipeline.yaml; do oc apply -f $yaml; done
Démarrer les pipelines Tekton.
for yaml in examples/*/tekton/pipelinerun.yaml; do oc create -f $yaml; done
Tâches tekton
La tâche buildah-build construit une image de conteneur en utilisant la commande buildah. Les spécificités de cette tâche sont liées au pré-requis nécessaire à l’exécution de buildah en conteneur.
- Le répertoire de travail de buildah (/var/lib/containers) est un volume emptyDir.
- La variable d’environnement
STORAGE_DRIVER=vfsdésactive l’utilisation de overlayfs. - Enfin, la capability SETFCAP est affectée à buildah.
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: buildah-build
spec:
params:
- name: context-dir
type: string
default: .
- name: containerfile-path
type: string
default: Containerfile
workspaces:
- name: source-workspace
description: Workspace containing source code
- name: oci-images
mountPath: /srv/oci-images
volumes:
- name: container-storage
emptyDir: {}
steps:
- name: build
image: registry.redhat.io/rhel8/buildah:8.9
env:
- name: STORAGE_DRIVER
value: vfs
script: |
#!/bin/bash
set -Eeuo pipefail
buildah bud -t localhost/image:$(uname -m) -f $(workspaces.source-workspace.path)/$(params.containerfile-path) $(workspaces.source-workspace.path)/$(params.context-dir)
buildah push localhost/image:$(uname -m) oci-archive:/srv/oci-images/$(uname -m).tar
securityContext:
capabilities:
add:
- SETFCAP
volumeMounts:
- name: container-storage
mountPath: /var/lib/containersLe script exécuté par cette tâche est concis (seulement deux étapes) :
- Il construit l’image de conteneur en se basant sur un Dockerfile / Containerfile.
buildah bud -t localhost/image:$(uname -m) -f $(workspaces.source-workspace.path)/$(params.containerfile-path) $(workspaces.source-workspace.path)/$(params.context-dir) - Il stocke une copie de l’image de conteneur dans le volume AWS EFS au format OCI.La commande
buildah push localhost/image:$(uname -m) oci-archive:/srv/oci-images/$(uname -m).tarbuildah pushpourrait nous laisser croire qu’on pousse l’image dans une registry distante. Mais comme l’image destination est préfixée paroci-archive:, buildah pousse en fait l’image sur le système de fichier (au format OCI).
La tâche buildah-push récupère depuis le volume AWS EFS les images générées par les multiples instances de buildah-build, les assemble sous la forme d’un manifeste multi-architecture et pousse le tout sur la registry.
Les spécificités de cette tâche sont majoritairement les mêmes que pour buildah-build. Seul un workspace additionnel nommé “dockerconfig” a été ajouté pour passer les credentials d’accès à la registry.
Mais attardons nous sur son script.
#!/bin/bash
set -Eeuo pipefail
# Handle registry credentials
if [[ "$(workspaces.dockerconfig.bound)" == "true" ]]; then
if test -f "$(workspaces.dockerconfig.path)/config.json"; then
export DOCKER_CONFIG="$(workspaces.dockerconfig.path)"
elif test -f "$(workspaces.dockerconfig.path)/.dockerconfigjson"; then
cp "$(workspaces.dockerconfig.path)/.dockerconfigjson" "$HOME/.docker/config.json"
export DOCKER_CONFIG="$HOME/.docker"
else
echo "neither 'config.json' nor '.dockerconfigjson' found at workspace root"
exit 1
fi
fi
declare -a iids=()
for arch; do
echo "Loading image for architecture $arch..."
iid=$(buildah pull oci-archive:/srv/oci-images/$arch.tar)
iids+=("$iid")
done
buildah manifest create localhost/multi-arch-image "${iids[@]}"
buildah manifest push --all localhost/multi-arch-image docker://$(params.image-name)
La première partie du script positionne la variable DOCKER_CONFIG qui sera utilisée par la commande buildah push pour s’authentifier sur la registry.
La seconde partie récupère les images des différentes architectures (commande buildah pull) et stocke leur Image ID dans une liste.
La commande buildah manifest create crée un manifeste multi-architecture avec la liste de toutes les images chargées précédemment.
Enfin, la commande buildah manifest push envoie le manifeste et les images sur la registry.
Pipeline “Containerfile”
Le premier cas d’usage présenté au début de cet article porte sur l’utilisation d’un Dockerfile / Containerfile pour construire une image de conteneur :
Construction d’une image depuis un Dockerfile / Containerfile. Une image de base multi-architecture est disponible dans une registry et le Dockerfile / Containerfile vient appliquer une série de modifications à cette image. L’image résultante est également multi-architecture.
Le pipeline correspondant récupère le code source, exécute un buildah build pour chaque architecture (x86_64 et arm64) et pousse le manifeste sur la registry.
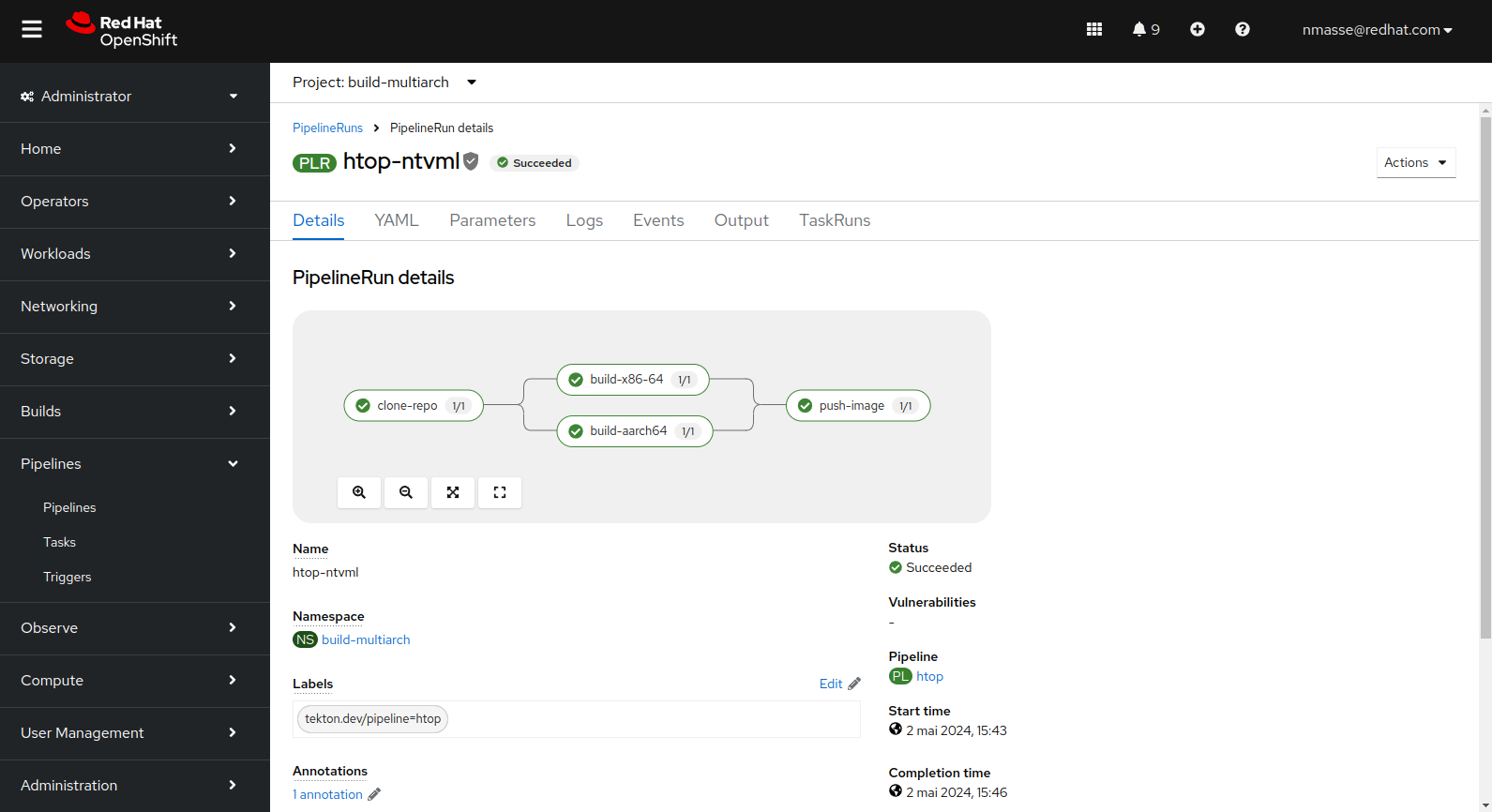
htop).L’image résultante sur la registry quay.io montre bien un manifeste contenant deux images : une pour x86_64 et une pour arm64.
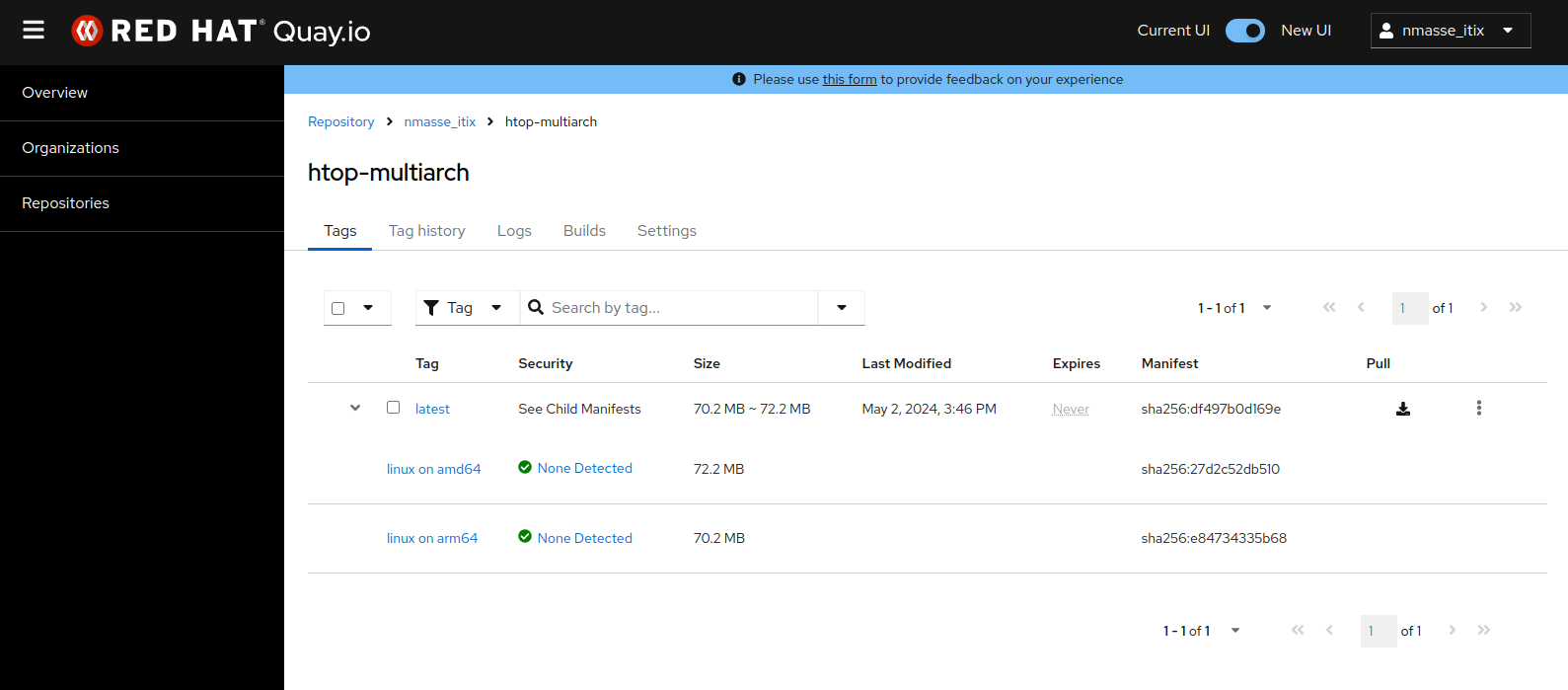
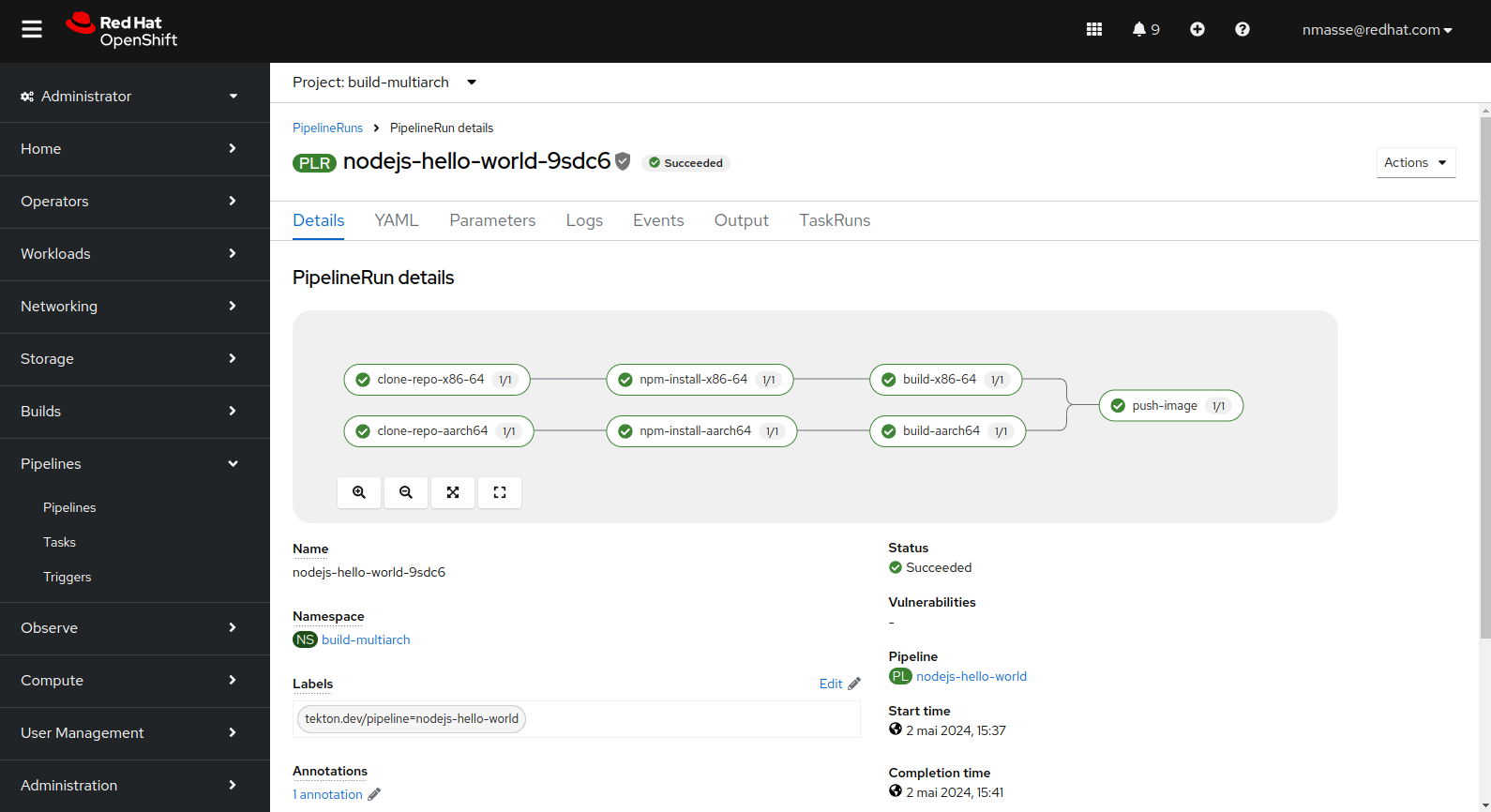
htop).Pipeline “NodeJS”
Le pipeline NodeJS est sensiblement différent dans le sens où le dépôt Git est récupéré deux fois : une fois pour chaque architecture.
La raison est que la commande npm install va télécharger les dépendances de l’application et certaines de ces dépendances peuvent embarquer du code natif (c’est le cas de certaines bibliothèques bas niveau). Il faut donc un workspace séparé pour chaque architecture.
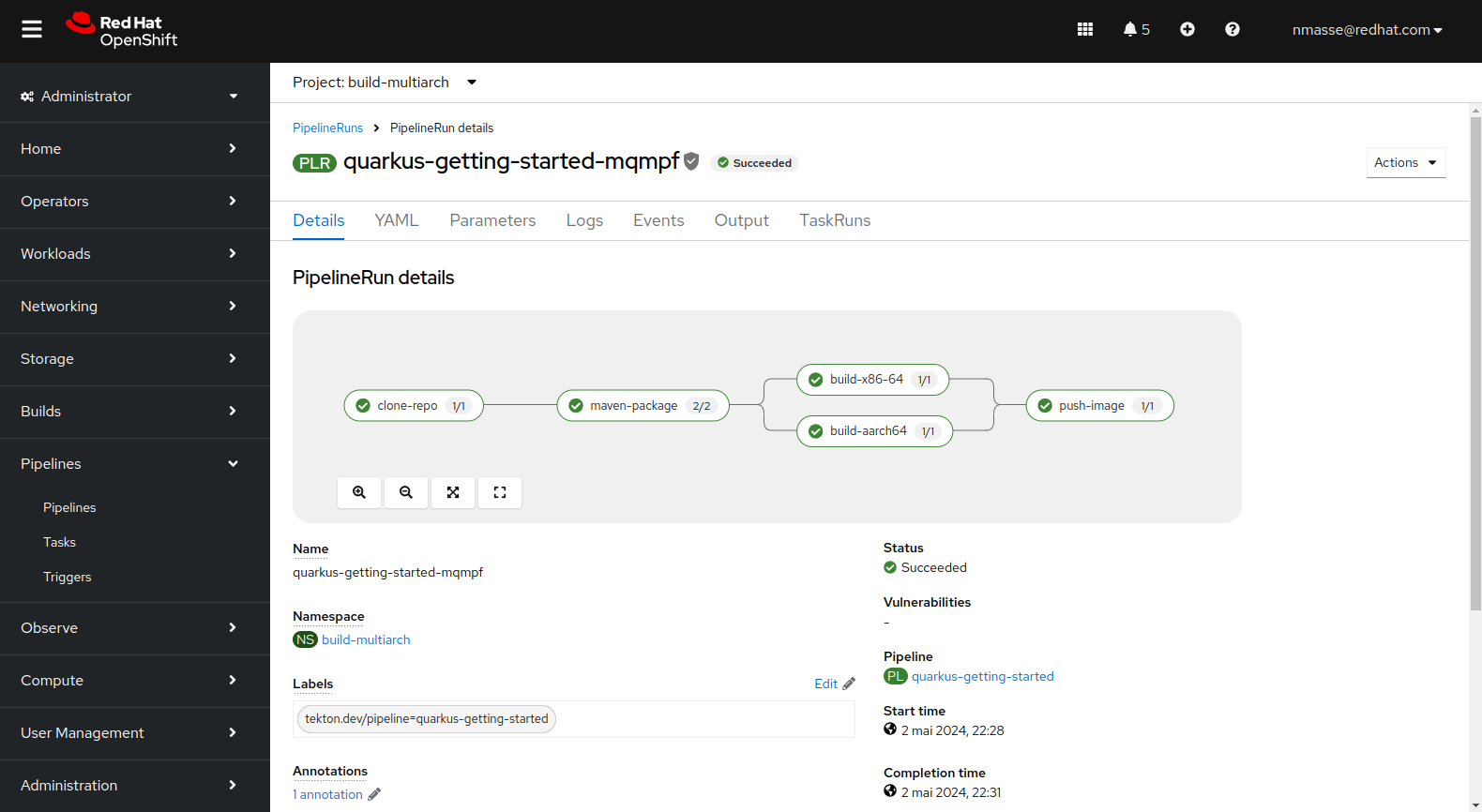
Pipeline “Quarkus”
Le pipeline Quarkus est encore différent du pipeline NodeJS dans le sens où l’application Quarkus est compilée en mode JVM et donc la compilation n’a lieu qu’une seule fois. Le bytecode contenu dans les fichiers Jar pouvant tourner de manière indifférenciée sur n’importe quelle architecture, il n’y a qu’un workspace Git partagé entre toutes les architectures.
Lier une tâche à une architecture
Jusqu’à présent l’article ne dit pas comment Tekton s’organise pour exécuter la tâche de construction de l’image x86_64 sur un noeud x86_64, l’image arm64 sur un noeud arm64, etc.
Il n’y a pas de magie ! Tout se passe dans le PipelineRun !
apiVersion: tekton.dev/v1
kind: PipelineRun
metadata:
generateName: htop-
spec:
pipelineRef:
name: htop
params:
- name: git-url
value: https://github.com/nmasse-itix/tekton-pipeline-multiarch.git
- name: image-name
value: quay.io/nmasse_itix/htop-multiarch
- name: context-dir
value: examples/htop/src
- name: containerfile-path
value: "examples/htop/src/Containerfile"
workspaces:
- name: oci-images
volumeClaimTemplate:
spec:
storageClassName: efs-csi
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
- name: source-workspace
volumeClaimTemplate:
spec:
storageClassName: efs-csi
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
- name: registry-token
secret:
secretName: quay-authentication
taskRunTemplate:
serviceAccountName: buildbot
taskRunSpecs:
- pipelineTaskName: build-x86-64
podTemplate:
nodeSelector:
beta.kubernetes.io/arch: amd64
- pipelineTaskName: build-aarch64
podTemplate:
nodeSelector:
beta.kubernetes.io/arch: arm64Le champ taskRunSpecs permet d’ajouter des contraintes d’exécution à une ou plusieurs tâches du pipeline.
Dans l’exemple ci-dessus, le PipelineRun contraint l’exécution de la tâche build-x86-64 sur un noeud ayant l’étiquette beta.kubernetes.io/arch=amd64 et la tâche build-aarch64 sur un noeud ayant l’étiquette beta.kubernetes.io/arch=arm64.
Conclusion
Dans cet article, nous avons passé en revue la configuration nécessaire à la construction d’images multi-architecture dans un environnement OpenShift dans le Cloud AWS. Trois cas d’usage ont été implémentés : construction d’une image à partir d’un Dockerfile / Containerfile, construction d’une application NodeJS et enfin construction d’une application Quarkus.
Le code source et les manifestes sont présents dans le dépôt Git pour qui veut reproduire l’expérience.
Dernière modification le 30/08/2024